
„Ich tue immer das, was ich nicht kann, damit ich lernen kann, wie man es macht“
oder
„Ich mache immer das, was ich nicht kann, damit ich lerne, es zu können“
Pablo Picasso
Übersetzungen an sich, gar juristische Übersetzungen mithilfe artifizieller Intelligenz?
Künstliche Intelligenz (KI), Maschinelles Lernen (ML), Künstliche neuronale Netze, Tiefes Lernen, Maschinelle Verarbeitung natürlicher Sprache (NLP), Neuronale maschinelle Übersetzung (NMT) und Große Sprachmodelle (LLMs) sind Begriffe, von denen jede Übersetzerin und jeder Übersetzer schon einmal gehört haben sollte.
Nicht zweckgebundene, einfache artifizielle Intelligenz, mitunter als generische KI bezeichnet und neuerliche, sogenannte generative KI zur Sprachübersetzung allgemein und zur juristischen Übersetzung insbesondere, sind Themen, mit denen ich mich schon seit langer Zeit auseinandersetze.
Daher möchte ich an dieser Stelle die Gelegenheit nutzen, bestimmte Einzelheiten näher zu erläutern und anhand einiger konkreter Beispiele zu untermauern.
Meine Herangehensweise ist eine induktive: Aus der Erfahrung mit künstlicher Intelligenz im Zuge meiner Eigenschaft als Rechts- und Sprachsachverständiger und meiner Tätigkeit als Übersetzer, Fachlektor und Spezialist für die Revision von Rechtsübersetzungen schließe ich auf die Beschaffenheit sogenannter maschineller Verarbeitung natürlicher Sprache spezifisch im Rechtswesen, somit auf die Eigenschaft erwähnter generativer artifizieller Intelligenz über den Rechtsbereich hinaus ganz allgemein.
Denn künstliche Intelligenz im Zuge täglicher Arbeit von Übersetzerinnen und Übersetzern ist nämlich gar nicht so neu, wie es in Anbetracht einer gehypten medialen Öffentlichkeit erscheinen mag. Der Umgang damit ist, in Ansätzen jedenfalls, der Fachübersetzerin und dem Fachübersetzer, und somit der geübten Anwenderin und dem geübten Anwender der Rechtsübersetzung, in aller Regel schon jahrzehntelang bekannt!
Wie ist das gemeint und worauf bezieht sich das?
Gemeint ist die Möglichkeit, sich unter Anwendung der sogenannten Booleschen Operatoren den von gängigen Suchmaschinen indexierten Teil des World Wide Web als Korpus zugänglich machen zu können, wobei die folgenden Ausführungen dazu dienen sollen, sich diese gewissermaßen indirekt generierten Korpora auch in der Tat zugänglich zu machen!
Weil, es erregt Erstaunen, dass, soweit ich dies anhand von mir geprüfter Texte nachvollziehen kann, bis heute meist in eher bescheidenem Umfang von diesen doch so nahe liegenden und verhältnismäßig einfachen und, wenn man so möchte, althergebrachten Möglichkeiten künstlicher Intelligenz Gebrauch gemacht wird, zumal sich die am häufigsten verwendete Suchmaschine Google für diese Zwecke hervorragend eignet!
Nützlich ist, bzw. wäre da zunächst dreierlei, nämlich:
- a) die Funktion Hochkommata [“…”], um die Anwendbarkeit und Eignung eines bestimmten Passus zu überprüfen, genauer zu verifizieren, bzw.
- b) der kombinierte Einsatz der Funktion Hochkommata [“…”] und der sogenannten Trunkierung mittels der Platzhalterfunktion Asterix [… * …], um sich möglicher Alternativen zu vergewissern oder
- c) wiederum die Funktion Hochkommata [“…”] um zu erfahren, wie ein Satz zu Ende gebracht werden kann.
Interessanterweise sind eben jene Funktionalitäten, nämlich die:
- unter b) aufgeführte, also die mögliche Substituierbarkeit bestimmter Elemente eines phraseologischen Konstrukts genau dasjenige, um das sich vor allem auf dem Prinzip der Kodierung und Dekodierung beruhende Bild-Text-Code-Erzeugende generative vorab trainierte Transformer im Wesentlichen drehen,
- unter c) gezeigte dynamische semantische Ergänzung, oder besser gesagt Vervollständigung angefangener Wortfolgen, genau dasjenige, um das sich autoregressive Sprachmodelle ganz allgemein im Wesentlichen drehen!
Stichworte dabei: Kollokationen, also feste Wortverbindungen und Rekurrenz, also deren wiederholte Verwendung. Und wiederum interessanterweise ist in diesem Zusammenhang die Rede von semantischen “Räumen” bzw. sich aus dem Kontext ergebenden “Räumen“.
Es geht, rein auf Textgenerierung bezogen, bei diesen Modellen nämlich darum, anhand megalomanischer Datensätze als Zweck und Basis, sowie Training auf deren Grundlage als Mittel und Ergebnis, Texte quasi sich selbst schreiben zu lassen und zwar nach dem Prinzip: Woher soll ich (das Modell) wissen, was ich denke, bevor ich sehe, was ich schreibe.
In der englischen Ausgabe der Financial Times ist kürzlich ein sehr nützlicher Artikel erschienen, in dem Schritt für Schritt nachvollziehbar dargelegt wird, wie genau dies im Einzelnen funktioniert.
Um nun besser zu verstehen, was solche Transformer anstellen, sei hier ferner die Möglichkeit in Erinnerung gerufen, auf Boolesche Weise:
- d) sowohl kumulativ als auch alternativ zu suchen, also mittels der sogenannten Und-Verknüpfung [… + …], hier müssen beide Termen/Phrasen vorhanden sein, um das gewünschte Ergebnis hervorzurufen,
- e) kumulativ oder genau so alternativ, also mittels der sogenannten Oder-Verknüpfung [… | …], hier muss nur ein Terminus/Phrase vorhanden sein, um das gewünschte Ergebnis hervorzurufen,
oder, weit erheblicher, ebenso umgekehrt, nämlich
- f) kumulativ und entschieden nicht alternativ [… +/- …], also mittels der sogenannten Ja-aber-nicht-Verknüpfung, hier müssen ein Terminus/Phrase oder mehrere Termen/Phrasen vorhanden sein, der/die expressis ausgeschlossene(n) aber entschieden nicht, um das gewünschte Ergebnis hervorzurufen.
Diese grundlegenden Booleschen Funktionalitäten sind, wenn man so will, als alte Zöpfe und Hüte Instrumente umfassender Nützlichkeit in der Hand der Fachübersetzerin und des Fachübersetzers!
Boolesche Operatoren als einfache artifizielle Intelligenz, mit deren Hilfe sich eine zielgerichtete und hoffentlich zielführende Korpus-Suche – umstandslos über die Suchmaschinen Google oder DuckDuckGo – bewerkstelligen lässt, sind unzweifelhaft probat bewährtes Mittel und etablierte Methode, um linguistisch motivierte Suchaktionen jedmöglicher Art im weltweiten Datennetz anzudenken, anzuschieben und also zu realisieren!
Andenken, Anschieben und demzufolge realisieren: Die Rede ist in diesem Zusammenhang, leicht hyperbolisch, vom Prompt-Engineering – natürlich-sprachlichem Input einem KI-Sprachmodell gegenüber. Dazu aber später mehr!
Alles dies gar nicht so neu, also? Ja möchte, ja könnte man sagen!
Die Frage nun: Wie lässt sich die Routine der Korpus-Suche mithilfe Boolescher Operatoren übertragen auf das, was bezeichnet wird als Sprachmodellierung (Language Modelling), bzw. maschinelle Verarbeitung natürlicher Sprache (Natural Language Processing bzw. NLP)?
Also eben jene grundlegenden Sprachmodelle (Foundation Models), genauer große Sprachmodelle (Large Language Models bzw. LLMs) und noch genauer aktuell die bereits erwähnten sogenannten Transformermodelle zum ausschließlichen Zweck der Fachübersetzung, nämlich als Anregung, Hilfe und Unterstützung für die Übersetzung ganz allgemein und speziell die juristische Übersetzung,
- g) um dies eingänglicher darzustellen, oder besser gesagt, die jeweiligen Einzelheiten gedanklich miteinander zu verknüpfen, sei noch hingewiesen auf einen weiteren Operator, oder Parameter, nämlich die AROUND-Funktionalität [… AROUND …].
In den im folgenden angegebenen beiden Beispielen gilt es zu erkunden, in welchem semantischen Verhältnis zueinander maschinelles Lernen und große Sprachmodelle stehen, buchstäblich und sinngemäß!
Gerade in Bezug auf das tiefere Verständnis von Sprachmodellierung und maschineller Verarbeitung natürlicher Sprache allgemein, und insbesondere des einem Transformermodell eigenen sogenannten Aufmerksamkeitsmechanismus, erweist sich dieser letztere als der wohl avancierteste aller Booleschen Operatoren:
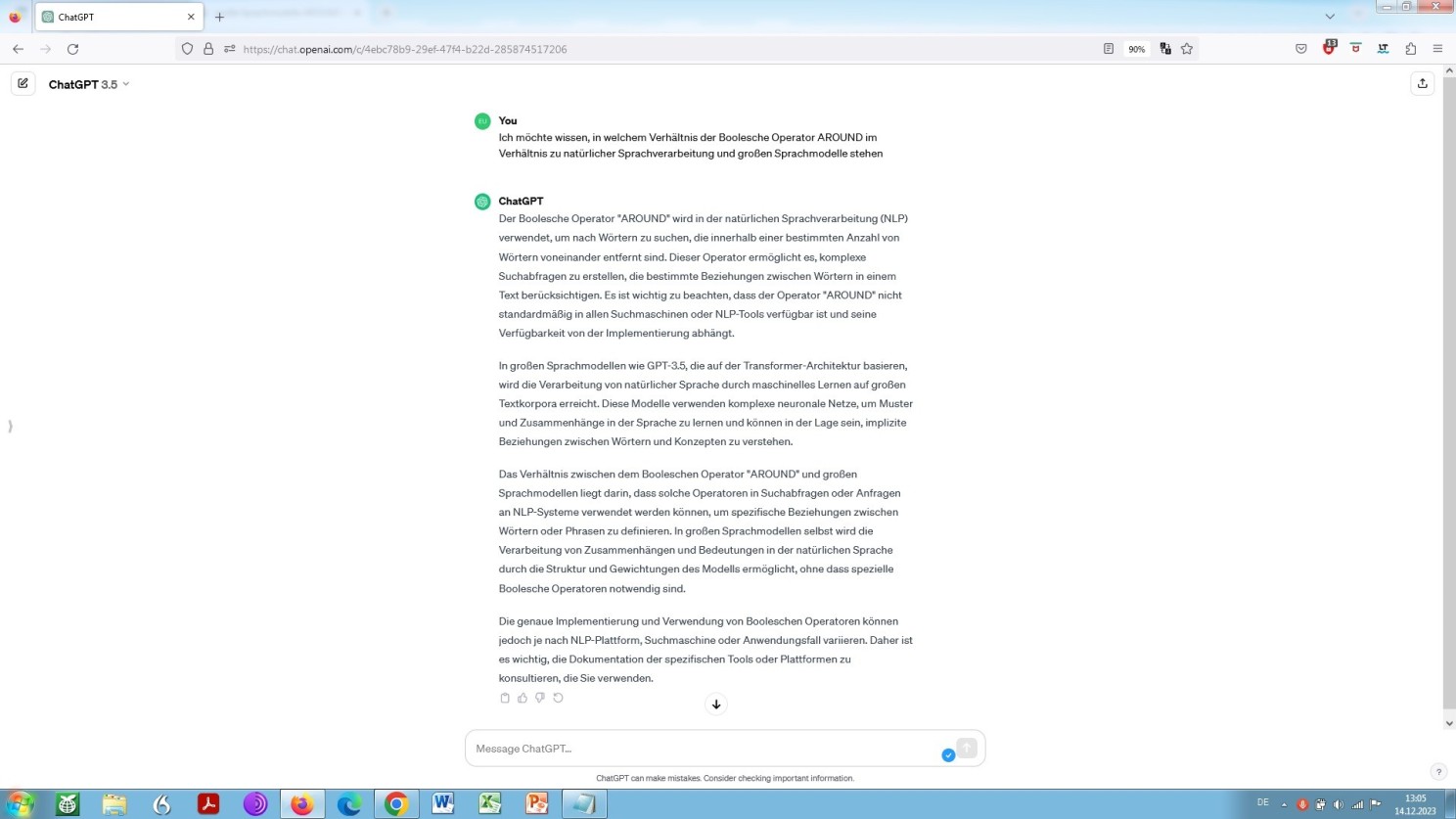
ChatGPT zum indirekten Verhältnis Boolescher AROUND-Operator, maschinelles Lernen und große Sprachmodelle
Tieferes Verständnis anhand einer konstruierten aber doch naheliegenden Analogie zwischen der sogenannten maskierten Sprachmodellierung und dem sogenannten Wiederauffinden von Information!
Vergleichbar den Booleschen Operatoren beim sogenannten Information-Retrieval anhand spezifischer Suchkontexte in Datennetzen lässt sich nunmehr beim Einsatz von solchen Modellen zum ausschließlichen Zweck der Übersetzung von Text aus einer Sprache in die andere an Stellschrauben drehen.
Oder, anders gesagt, es stehen maßgebliche Operatoren zur Verfügung, nämlich drei an der Zahl.
Man könnte es noch anders und besser so sagen: Es lassen sich verschiedene Parameter, die Rede ist von sogenannten Hyperparametern, voreinstellen und somit das Ergebnis der Ausgabe beeinflussen.
Soweit mir dies nun als Laie in Sachen Computerlinguistik festzustellen möglich ist, gibt es von diesen Hyperparametern eine ganze Reihe, die sich u.a. auf die Quantität der zu generierenden Ausgabe beziehen. Bezüglich der Qualität der Ausgabe – und also in unserem Falle der Qualität der zu vollführenden Rechtsübersetzung – sind indessen lediglich drei dieser Hyperparameter von erheblichem Interesse.
Zunächst wäre da der Hyperparameter Temperatureinstellung. Was hat es damit auf sich? Und ist eine Anpassung dieses Hyperparameters bei der Nutzung eines großen Sprach- bzw. Transformermodells überhaupt sinnvoll (situationsbedingt), und so ja, ist sie dies zum Zwecke der Sprachübersetzung (situationsadäquat)?
Nun, ein großes Sprachmodell wäre kein solches, ließe sich dieses nicht gegebenen- ja erforderlichenfalls um eine Selbstauskunft bitten:
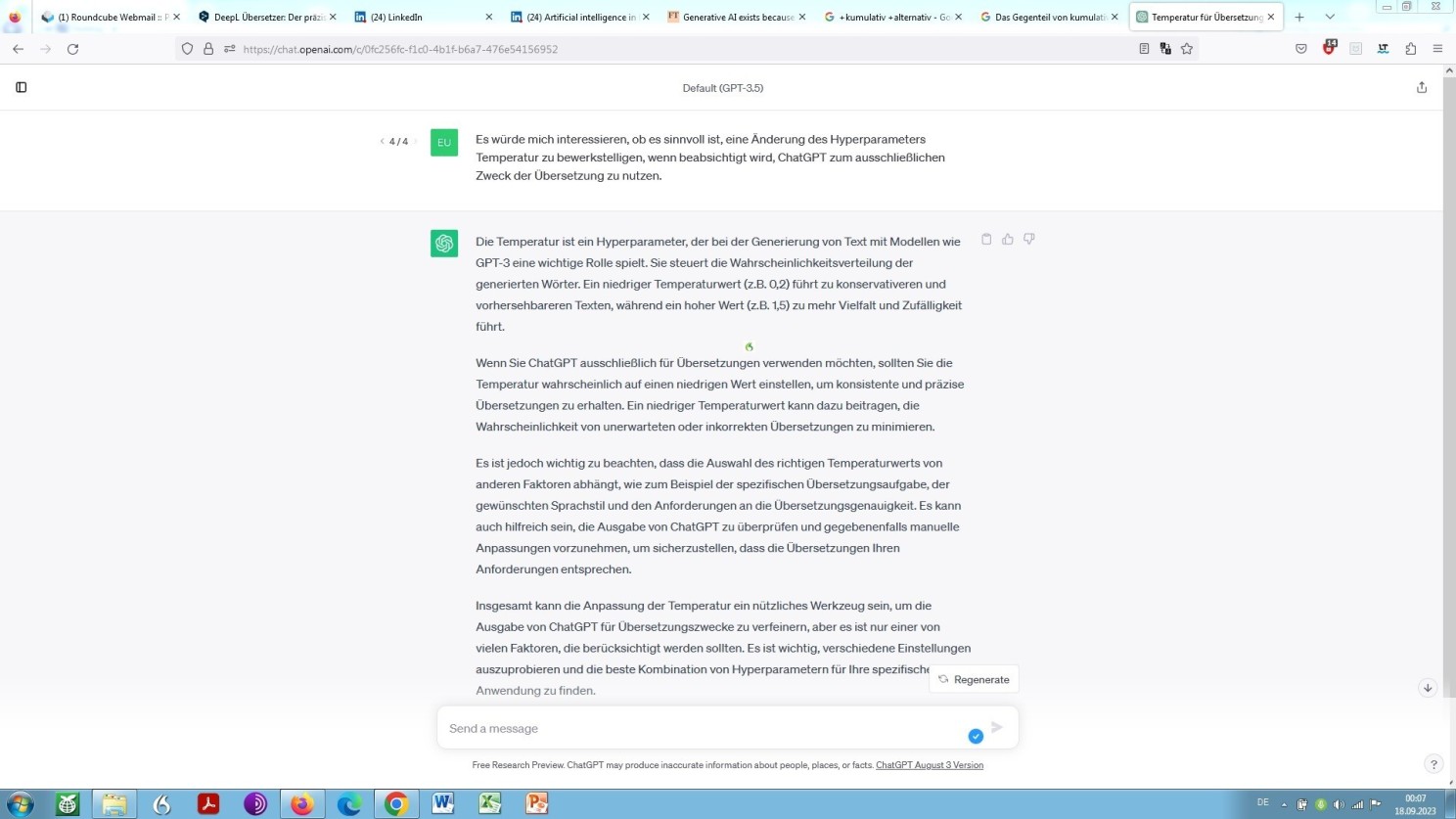
Selbstauskunft von ChatGPT zum Hyperparameter Temperatur
Ganz allgemein, aber insbesondere auch bei der Verwendung eines Transformermodells zum Zwecke der Übersetzung aus einer Sprache in die andere, könnte eine Erhöhung der Temperatur zu mehr Zufälligkeit Anlass geben, was wiederum wahrscheinlicher-, aber eben nicht zwangsläufigerweise zu vielfältigeren oder kreativeren Ergebnissen führen würde.
Machen wir die Probe aufs Exempel anhand eines kurzen, aber schwierigen niederländischen Rechtstextes, den wir uns ins Deutsche übersetzen lassen – und der im weiteren Verlauf dieser, meiner Auseinandersetzung immer wieder Verwendung finden wird als ‘unser Beispiel‘:
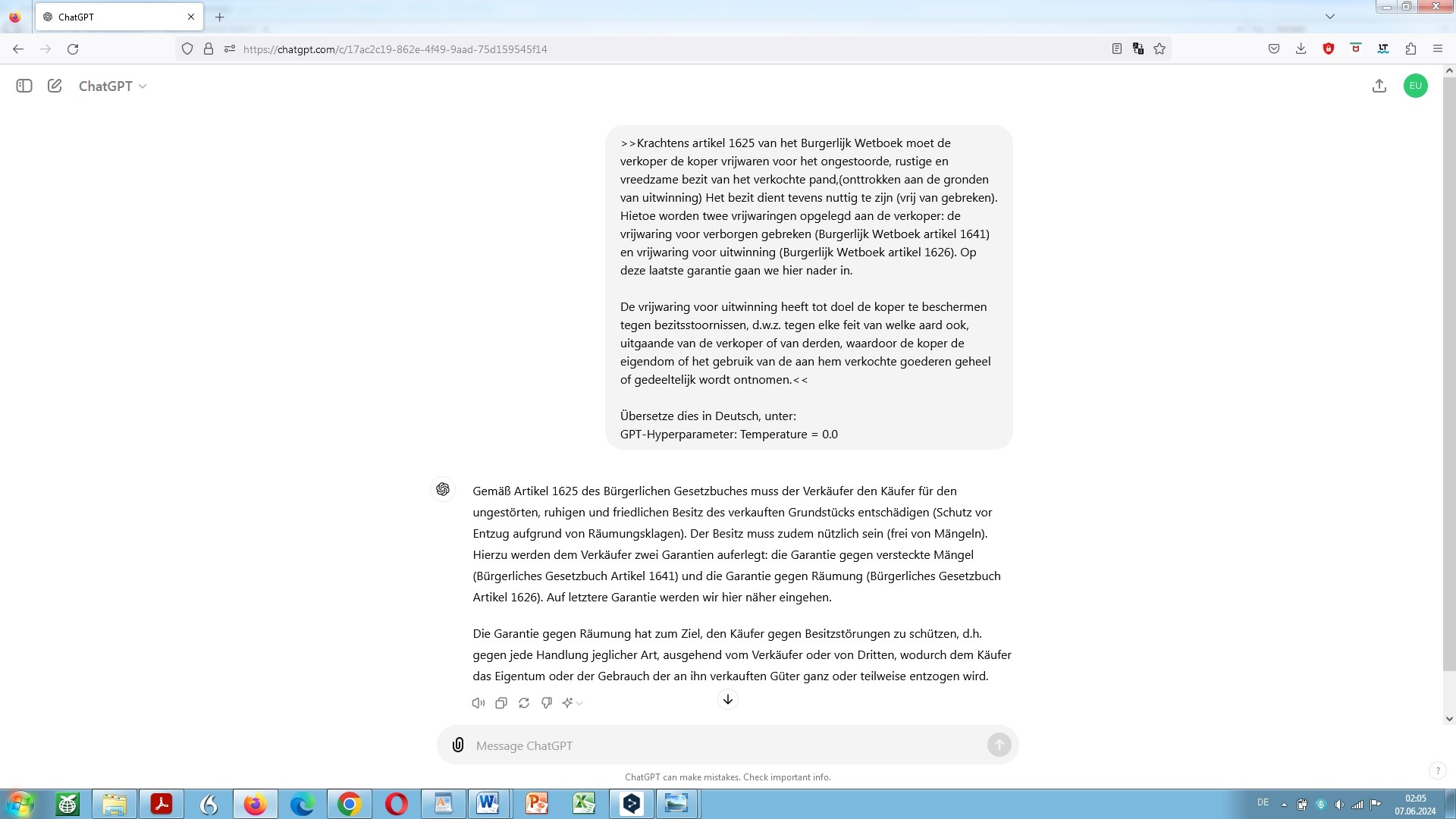
niederländischer Rechtstext zur Übersetzung angedient, hier unter Vorgabe des GPT-Hyperparameters ‘Temperatur’
Wie in Teilen schon erläutert, bedeutet eine niedrige Temperatur, dass vom Modell alternativlos ausgewählt wird das dem Modell am wahrscheinlichsten erscheinende sogenannte Folgetoken, also Wortbestandteil, Wort oder sehr kurze Wortfolge.
Ein Token im hiesigen Zusammenhang. Was genau ist das? Lassen wir das Modell selbst sprechen. Denn, apodiktisch betrachtet: Wäre es nicht in der Lage über sich selbst eine valide Auskunft zu erteilen, über was dann?
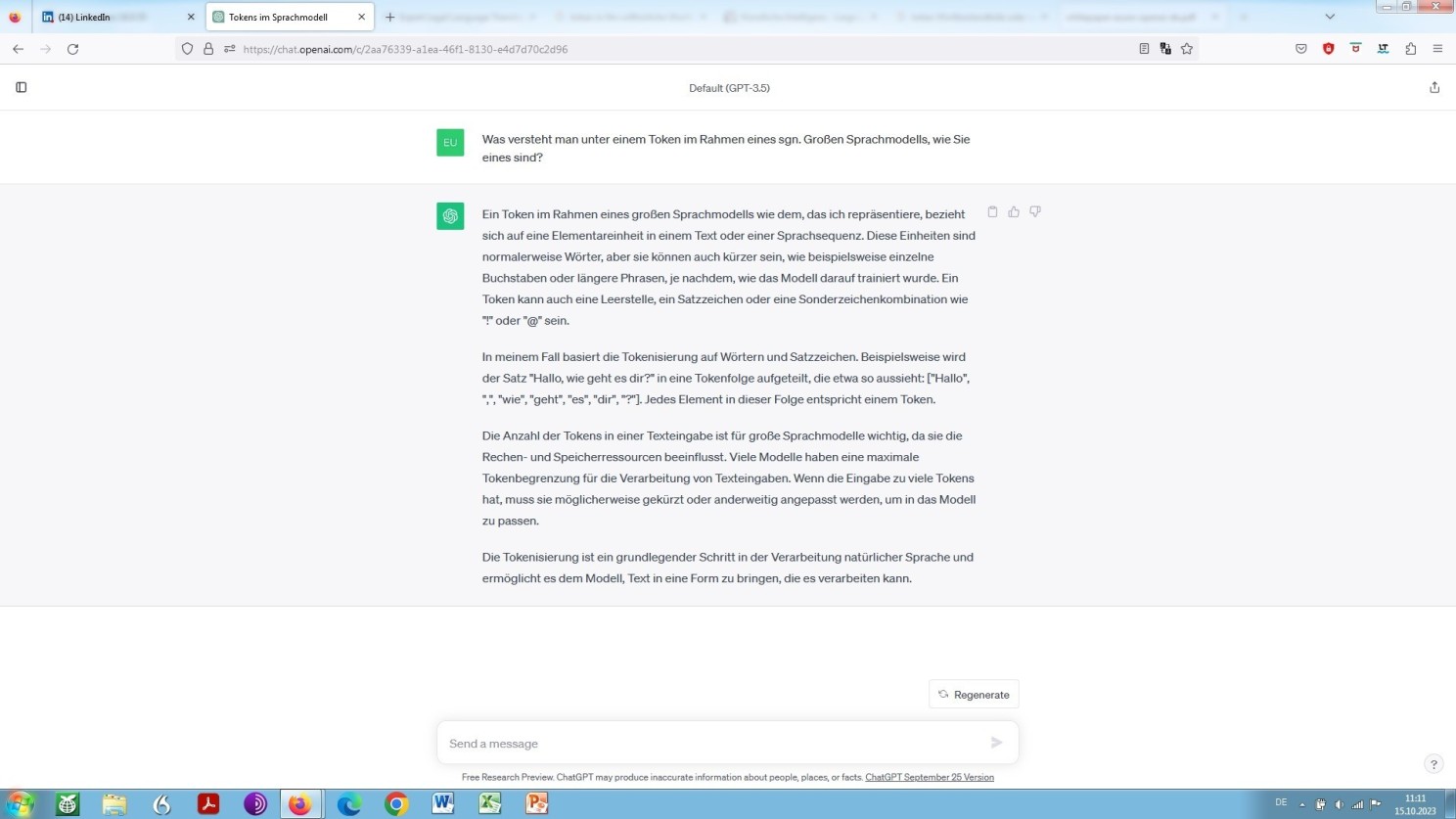
ChatGPT zur sgn. Tokenisierung in computerlinguistischem Zusammenhang, also das Zerlegen in Konstituenten
Wobei der hier beschriebene Prozess in der Regel auf der Grundlage eines sogenannten Greedy Search abläuft. Was hat es damit wiederum auf sich? Lassen Sie uns ChatGPT erneut um eine Selbstauskunft diesbezüglich bitten:
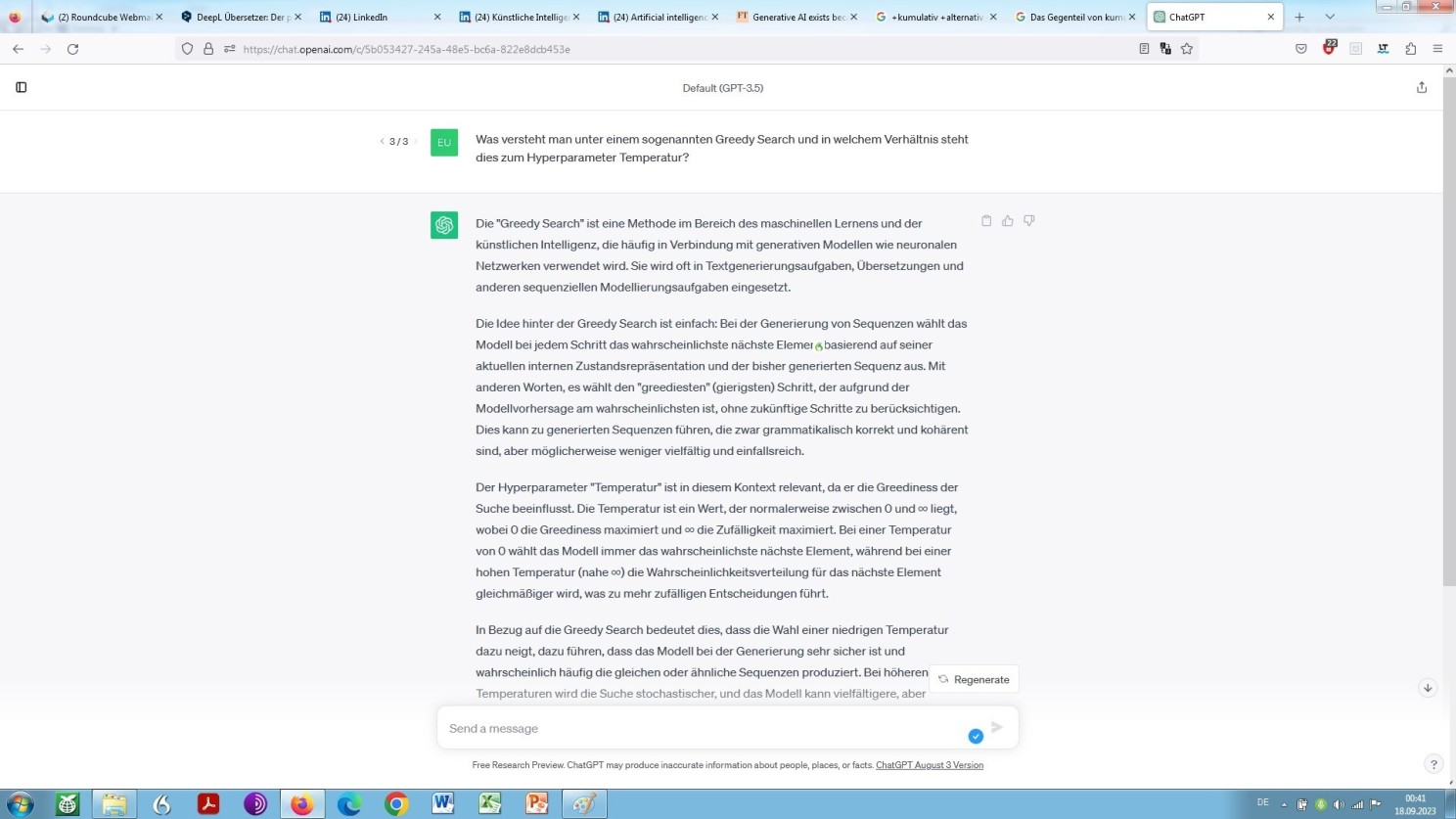
Selbstauskunft von ChatGPT zum Verfahren des sgn. Greedy Search
Niedrige Temperaturen, in unserem Beispiel ein Wert von null, wird demzufolge Übersetzungen ergeben, die primär zu inhaltlicher Sicherheit, aber zugleich zu sprachlicher Langweile tendieren. Für unser konkretes Anliegen, nämlich als Kriterium für juristische Übersetzungen, die automatisiert zu generieren sind, sollte dies daher als nicht ungeeignet erscheinen, sagen wir es so.
Und, rein auf die sprachlichen und weniger auf die inhaltlichen Aspekte bezogen, könnte man sagen: Je niedriger die Temperatur desto ausgeprägter die Neigung zu einfachem ergo bewährtem Suchen und Finden durch das Modell, nämlich im Ergebnis zur weit möglichsten sogenannten lexikalischen Simplifizierung und infolge dessen zu Wortarmut also der Ausgabe eines vergleichsweise geringen Wortschatzes bei zugleich auffallend immer gleichem Duktus!
Eine steigende Temperatur bedeutet nun ein Mehr an Miteinbeziehung möglicher Folgetoken, und zwar auf Grundlage des sogenannten Beam Search, wirkt also, wenn man so möchte, dieser lexikalischen Vereinfachung und immer gleich wirkenden Art und Weise des ‘Sprechens’ entgegen:
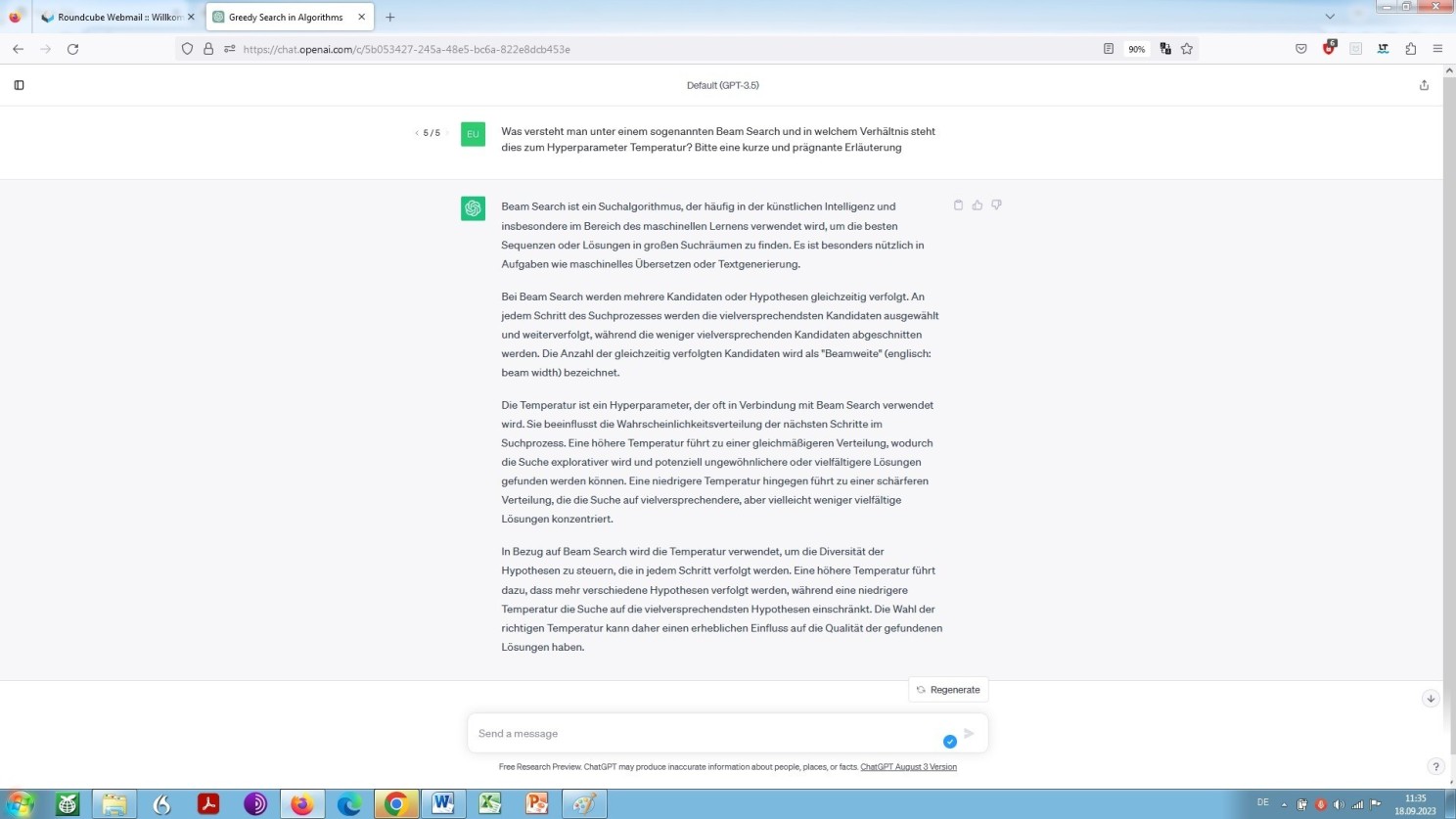
Selbstauskunft von ChatGPT zum Verfahren des sgn. Beam Search
Den aufgeführten Selbstauskünften aus der Blackbox, aber auch seriösen, das heißt nachvollziehbaren Quellen zufolge, würde eine Erhöhung der Temperatur nun zu mehr Unvorhersehbarkeit und somit auch Überraschungen führen, weil sie eben das Modell zur Erwägung zwingt, Umwege zu nehmen und es derart zu förmlich inkonsequenten, somit nicht vorhersehbaren Ergebnissen anregt.
Dies geschieht durch Folgetoken zu berücksichtigen, die es, also das Modell, sonst in der Regel unberücksichtigt lassen würde. Spiegelbildlich würde eine vergleichsweise hohe Temperatur – natürlich, könnte man fast sagen – auch die Anfälligkeit für Fehlangaben vergrößern.
Salopp zusammenfassen ließe sich dies nun wie folgt: Je höher die Temperatur, desto offener Tür und Tor für Fehlübersetzungen. Umgekehrt gilt indessen ebenso die – nicht unbedingt auf den rechtlichen Bereich bezogene, indes ganz allgemein wichtige – Erfahrung: Je niedriger die Temperatur, desto geringer die Chance des Effekts einer Erkenntnis oder gar Verwunderung in der Eigenschaft eines menschlichen Übersetzers: ‘Das hätte mir selbst nicht besser einfallen können! Wo hat er/sie also das Modell, dies her?’
Oder um es nun nochmals eher fachlich zu bestimmen: Niedrige Temperatur neigt zu deterministischer, ja statistischer Methode. Und je höher dann die Temperatur, desto probabilistischer, ja stochastischer die Methode, um die wahrscheinlichste Übersetzung für eine bestimmte Eingabe abzuleiten.
Nun ist neben OpenAI ChatGPT bzw. GPT-4 seit einiger Zeit schon auch Google-Bard und neuerdings Google-Gemini, als maßgebliches und allgemein niederschwellig zugängliches grundlegendes Sprachmodell in Deutschland verfügbar und somit nutzbar.
Gegenüber OpenAI ChatGPT und GPT-4 vom Ansatz her (anfänglich) low profile, hat es Bard dennoch (und Gemini erst recht) ‘in sich’!
Um zunächst Bards Schwächen zu erfassen, wäre folgender Dialog zu besehen, aus dem erkennbar wird, mit welchen Beschränkungen, nämlich Art und Umfang des Halluzinierens, in einer Antwort Geminis zu rechnen ist (siehe zum Vergleich). Sie sehen, wie Bard bzw. Gemini einer für jeden ersichtlichen grottenfalschen Grundannahme zu (Schein-)Plausibilität verhilft. Darin erkenne ich das grundsätzliche Problem maschineller Verarbeitung natürlicher Sprache. Nicht in der unzutreffenden Grundannahme an sich, sondern in der damit einhergehenden Pseudoplausibilität. Dazu aber später noch mehr!
Um hingegen das Potenzial der Google Sprachmodelle zu ermessen, soll folgender Dialog dienen, der unschwer erahnen lässt, wohin die Reise möglicher- ja wahrscheinlicherweise gehen wird – auch und gerade im Bereich des Rechts und der Rechtsanwendung!
Aber, zu den Möglichkeiten und Unmöglichkeiten der Google Sprachmodelle, wie auch jeder anderen Form Tiefen Lernens auf der Grundlage neuronaler Netze zur Verarbeitung natürlicher Sprache generell, gleich noch weiteres!
Auch Bard, basierend auf einem LLM namens LaMDA (Language Model for Dialogue Applications), bietet Nutzern die Möglichkeit, an der Temperaturschraube zu drehen, wie aus entsprechender Selbstauskunft ersichtlich wird:
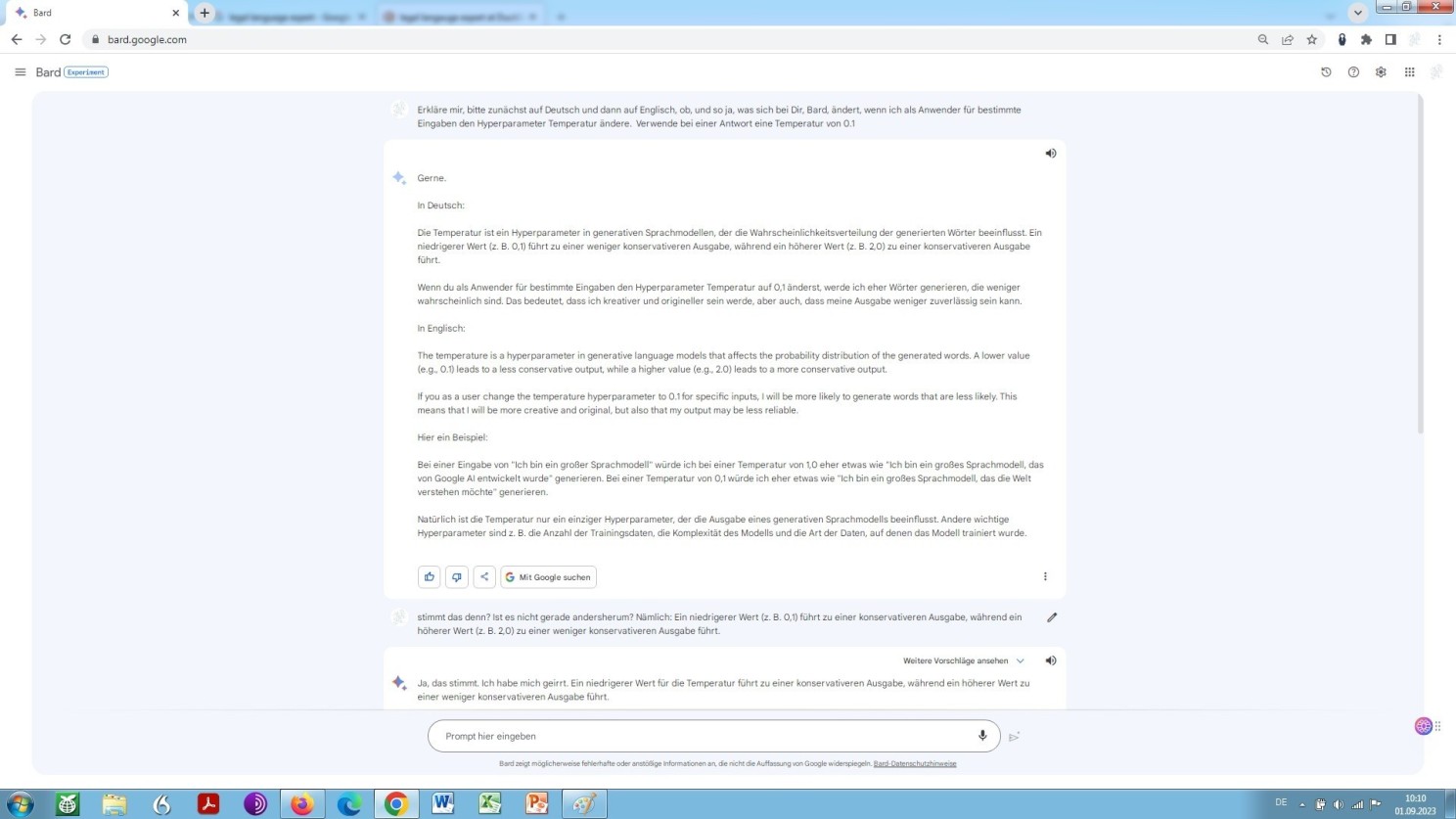
Selbstauskunft Google Gemini (Bard) zur Möglichkeit, den Hyperparameter Temperatur zu bestimmen
Kurz und bündig wird hier erklärt, worum es beim Hyperparameter Temperatur geht.
Dabei ‘leistet’ Bard sich jedoch eine grausige Verwechslung, nämlich die steif und steh-feste Behauptung des Gegenteils dessen, was ist. Ein Problem, ein generelles, der Sache inhärentes, sowohl die maschinelle Verarbeitung natürlicher Sprache ganz allgemein und im Zuge dessen beides betreffend, große Sprachmodelle und neuronale maschinelle Übersetzung (Neural Machine Translation) auf künstlichen neuronalen Netzen basierend, welche letztere im weiteren Verlauf dieser Auseinandersetzung noch näher beleuchtet werden wird!
Je intensiver mit jenen Mitteln gearbeitet, desto intensiver auch dieses Gewahr werden. Und spiegelbildlich gilt denn ebenso: Je mehr Verständnis dafür, wie künstliche neuronale Netze, Sprachmodellierung, Encoder-Only/Decoder-Only-Architekturen und Encoder-Decoder-Architekturen, Transformer, Aufmerksamkeit, bzw. Selbstaufmerksamkeit funktionieren, desto geringer die Verwunderung über genau dieses Phänomen.
Was hingegen die dargebotene modell-basierte Übersetzung, also die Übersetzungsleistung der Google Sprachmodelle in Bezug auf unser Standardbeispiel eines kurzen, aber überaus komplexen juristischen Textes anbelangt, kann sich das also Dargebotene im wahrsten Sinne der Wendung ‘sehen lassen’:
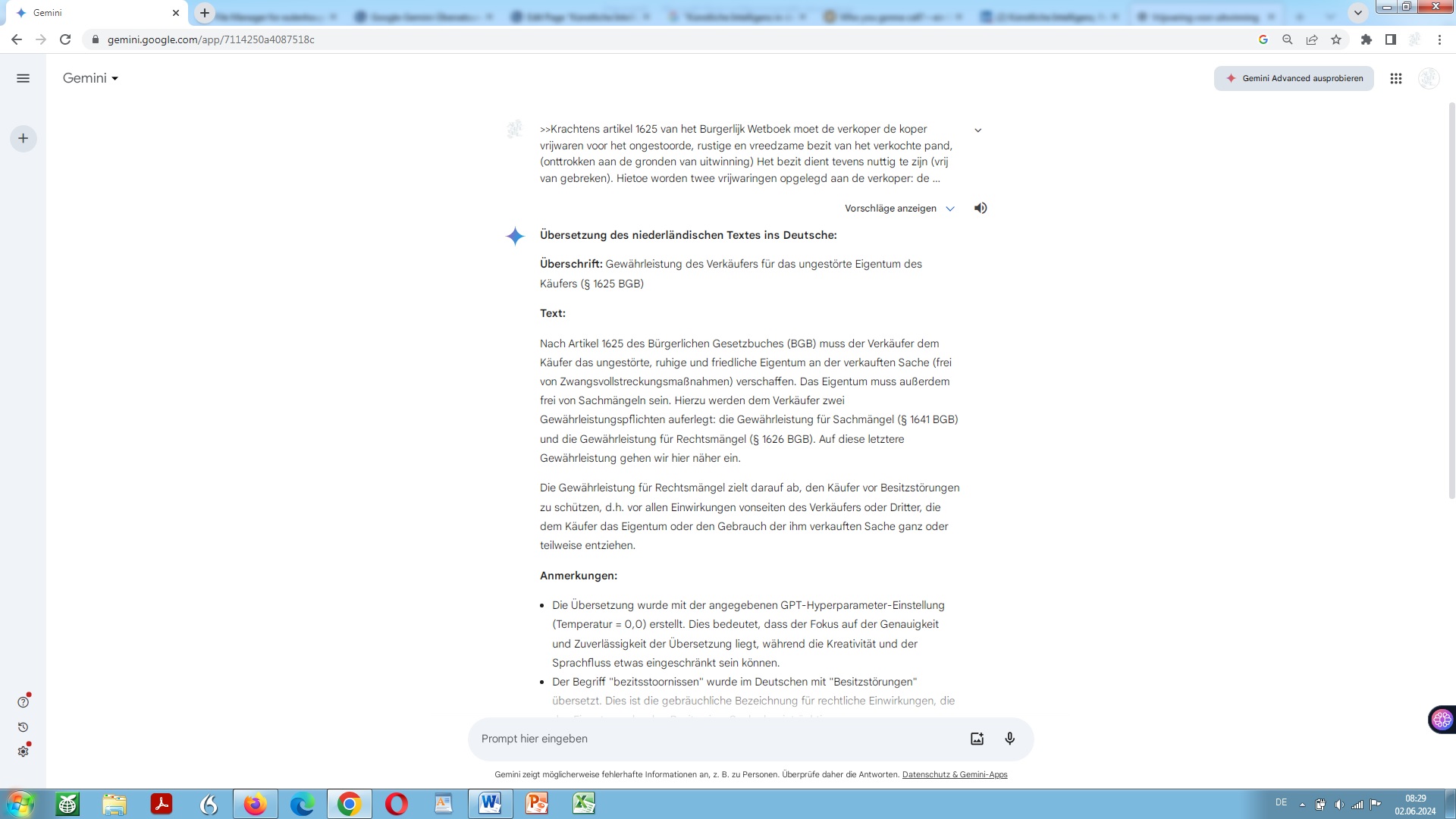
Google-Gemini-Übersetzung unseres Beispiels unbearbeitet
Egal aus welchem Blickwinkel man es betrachtet. Dargeboten wird hier schon regelrechter Übereifer, weil vom BGB im Quelltext gar nicht die Rede ist, und Google Gemini der subtilen Unterscheidung zwischen Besitz und Eigentum in der jeweiligen Jurisdiktion nicht gerecht wird, sie nicht zu erfassen mag, gleichwohl – vor virtuellem Selbstvertrauen nur so strotzend, so tut als ob! Konstruierte Plausibilität, Scheinplausibilität oder Pseudoplausibilität also!
Im jeweiligen Verglichen mit der Übersetzungsleistung der sogenannten grundlegenden Sprachmodelle ChatGPT und GPT-4 des Betreibers OpenAI, wie vorstehend dargelegt, und der Übersetzungsleistung neuronaler maschineller Übersetzung (NMT) wie nachstehend dargelegt, könnte, nach meinem Dafürhalten, die Google-Gemini-Übersetzung dennoch am ehesten herhalten als Grundlage, nämlich Rohübersetzung für eine nachträgliche Bearbeitung, also Nachbearbeitung durch einen sprachlich und juristisch unterlegten Post-Editor.
Wobei, Google wäre Google nicht, hätte man dort nicht bereits parallel an einem Alternativmodell gearbeitet, genannt: PaLM (Pathways Language Model), ein ‘transformer-basiertes Sprachmodell mit 540 Milliarden Schaltstellen’, daher ‘fast viermal so leistungsfähig wie LaMDA’.
Ob und in welchem Umfang Google Bard aktuell bereits vollständig von LaMDA auf PaLM umgestellt wurde bleibt wohl Betriebsgeheimnis. Den meisten Beobachtern zufolge, die sich selbst in der Sache Kompetenz beimessen, ist diese Umstellung bereits vollumfänglich vollzogen. Und, aus der soeben präsentierten Leistung als Fachübersetzer von verhältnismäßig hohem Niveau lässt sich indirekt herleiten, dass dem in der Tat so ist!
Jedoch, nicht nur das. Das aktuell zentrale Projekt in Forschung und Entwicklung, nicht nur, aber vor allem LLMs betreffend, heißt Zwilling oder Gemini. Die Benennung dieses Vorhabens deutet auf dessen Zweck, der darin besteht, beide bestehenden betriebsinternen Sparten der KI-Forschung zu fusionieren, mit dem Ziel, auf dem Gebiet der Verarbeitung natürlicher Sprache noch leistungsfähigere Modelle entwickeln zu können und zwar als multimodale Modelle, nämliche Modelle, die Informationen mehrerer Modalitäten verarbeiten können, einschließlich Bildern, Videos und Text.
Gestern noch multimedial, aktuell nun multimodal, wenn ich es richtig verstehe? Polemisierung könnte sich, in Anbetracht dessen, was da kommt, schon bald als unangebracht erweisen.
Aber, was nun kann ein auf PaLM basierendes Sprachmodell, was ein auf LaMDA basierendes bisher nicht konnte?
Der multimodale Ansatz zeigt sich nicht erst bei Gemini sondern bereits bei PaLM. Und außer, dass PaLM Metaphorik als solche erkennen und richtig interpretieren kann, jedenfalls der Ankündigung zufolge, kann es darlegen und somit begründen, wie und warum es zu dem Ergebnis kommt, zu dem es kommt.
Indes – im wahrsten Sinne – langer Worte kurzer Sinn, sehen Sie selbst:
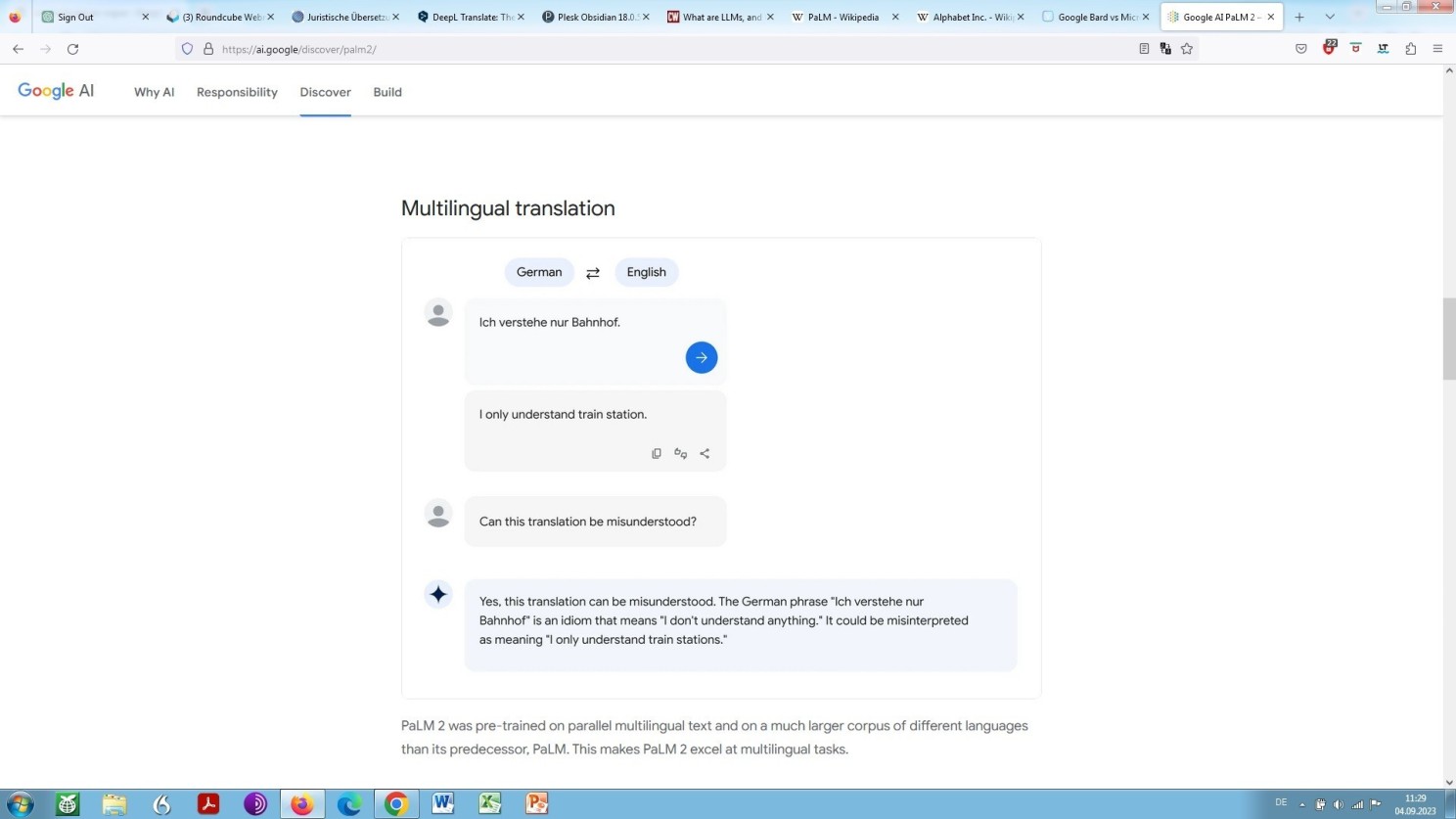
PaLM (Pathways Language Model)
Der Auskunft zufolge wurde das Vorabtrainieren von PaLM, im Gegensatz zu den Vorgängern LaMDA an parallel multilingualen also mehrsprachigen Texten und anhand eines weitaus umfassenderen Korpus unterschiedlicher Sprachen durchgeführt, soll sich also hervorragend eignen für das mehrsprachige Generieren verschiedener Texte, wie Vertragstexte (darüber zum Schluss dieser Abhandlung noch weiteres).
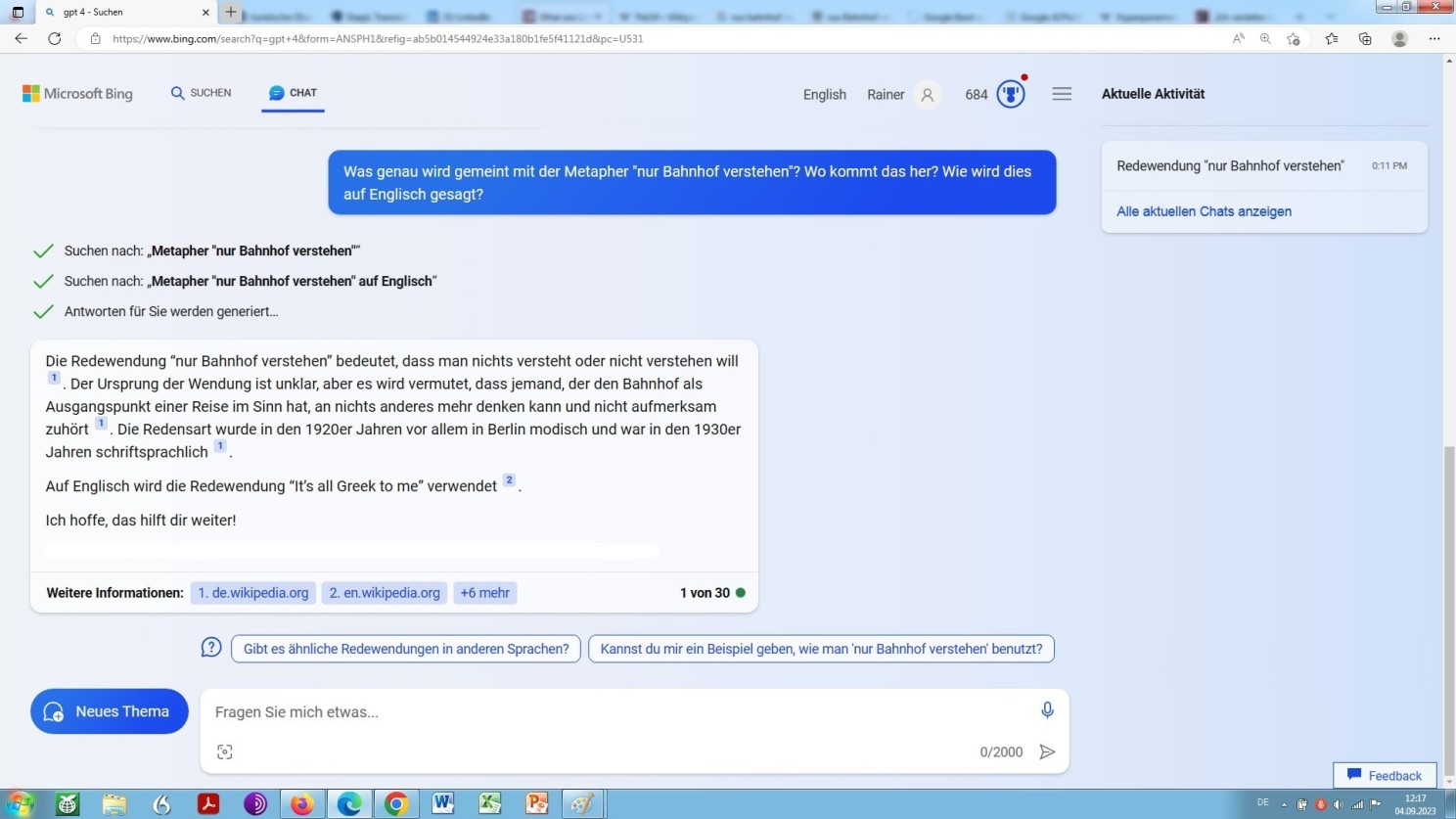
Möchte man sich nun mit der Antwort aus einer Blackbox, wie nachstehend noch näher beleuchtet, nicht zufrieden geben, etwa weil man Konfabulation oder Halluzination fürchtet, dient sich wiederum, als erste Stufe der Verifikation, wenn man so möchte, eine Befragung von GPT-4 an, auf welches sich über die Microsoft-Edge-Oberfläche zugreifen lässt, wobei die Einrichtung eines Nutzerkontos obligatorisch ist. Eine solche Befragung (von Bing AI!) ergibt zwar leider stets in der Länge – teilweise bis an die Schmerzgrenze – eingekürzte Antworten, legt aber im Gegensatz zu GPT Quellen offen, macht also im Wesentlichen nachvollziehbar, woher die Weisheit stammt, anstatt lediglich auf den sprichwörtlichen Zauberwürfel (Blackbox) zu verweisen. Aber, sehen Sie selbst:
Damit könnte man sich jetzt zufrieden geben. Möchte man das nicht, das heißt, möchte man sich vergewissern, vom LLM ausreichend informiert und nicht fehlinformiert zu werden, lässt sich eine traditionelle Google-Suche durchführen, als zweite Stufe der Verifikation, wenn man so will.
Desfalls kann diese traditionelle Google-Suche dann unter Zuhilfenahme Boolescher Operatoren geschehen, die hier, gekonnt eingesetzt, meist ganz schnell zu einem wirklich zufriedenstellenden, konkret zu folgendem Ergebnis führt:
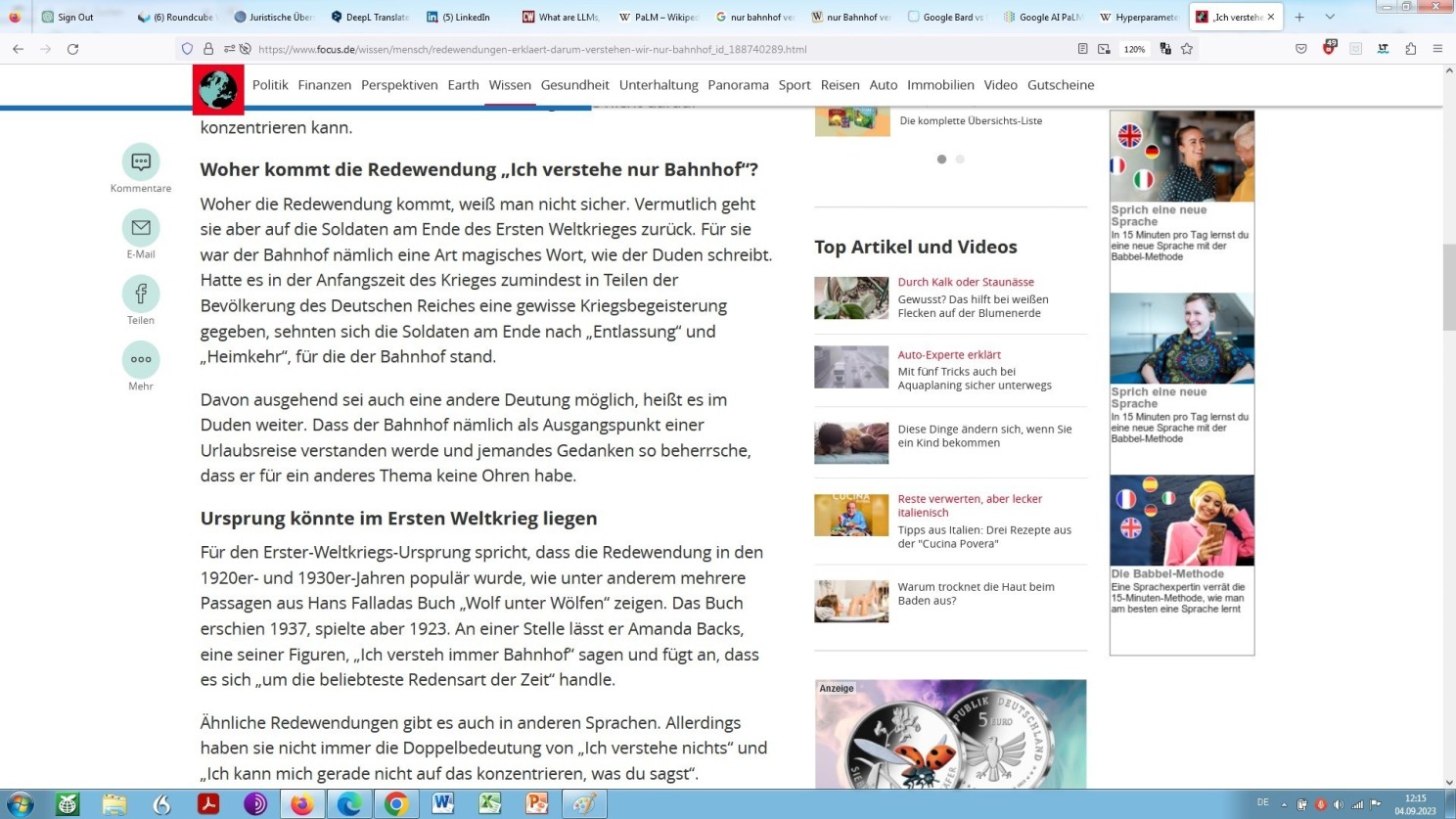
Ausschnitt aus dem Nachrichtenmagazin ‘Focus’
Das offenkundige Dilemma, dem sich Google ausgesetzt sieht: Je verbreiteter die avancierte Suche mithilfe von KI, desto gefährdeter die konventionelle Suche und somit das Kerngeschäft, nämlich der Verkauf nutzerbezogener Werbung.
Nicht unerwähnt bleiben sollte hier aber, dass auch OpenAI, jedenfalls dem Vernehmen nach und entgegen der weit verbreiteten Annahme, bisher mit ChatGPT und somit insgesamt, nicht profitabel arbeitet. Gleichwohl hier, systemimmanent, Investoren und Investorinnen – vor Geilheit nach künftigen Renditen, ergo Profiten mit den jeweiligen Beinen schlotternd, vom Unterleib über die Knie abwärts bis zu den Füßen, ja Zehenspitzen – bereitstehen, um Unsummen aufzubieten, oder zu versenken, in dieses neue wirtschaftliche Unterfangen namens KI: Du willst, ich will, wir wollen: Koste es, was es wolle!
Übrigens ist als Teil dieses Unterfangens noch ein dritter Spieler im Bunde mit Potenzial zur Entwicklung wegweisender maschineller Verarbeitung natürlicher Sprache. Nämlich ein Anbieter konkret niederschwelliger Nutzer-Features, somit NLP-Nutzung im betrieblichen Kontext und somit Grundlegendem Sprachmodell auch für die juristische Anwendung.
Gemeint ist der Anbieter Anthropic bzw. dessen Projekt, namens Claude. Claude 3 ist seit März 2024 in Kontinentaleuropa verfügbar und daher auch innerhalb der Europäischen Union experimentell nutzbar:
Claude 3 seit März 2024 europaweit nutzbar
Anders als mit den Wettbewerben GPT von OpenAI und Gemini von Google beginne ich geade, mit Claude 3 von Anthropic zu experimentieren.
Was sich aber jetzt schon sagen lässt, anhand einhelliger Einschätzungen von Leuten, die sich über ein sogenanntes VPN als Kunstgriff Zugang zu Claude 2 verschafft haben: vergleichsweise hohe sprachliche Brillanz bei vergleichsweiser geringer Faktizität.
Wäre dem auch unter Claude 3 so, ließe sich daraus schließen, dass die Standard-Hyperparametrisierung des Modells von der des direkten Konkurrenten als geschlossenes, grundlegendes, autoregressives Sprachmodell GPT von OpenAI stark abweicht, weil ja die computerlinguistischen Grundlagen beider Modellvarianten dieselben sind, ja sogar in Teilen von den gleichen Leuten entwickelt wurden und werden.
Denn, wenn nun in der Tat Claude 3 nach Verhältnismäßigkeit schöngeistig schreiben, dabei aber frequent das Blaue aus dem Modellhimmel heraushalluzinieren, ja vom Modellhimmel herunterlügen würde, müsse dies auf einen relativ hohen Standardtemperaturwert hindeuten, wie wir vorstehend bereits gesehen haben und auf eine relativ großzügige Wahrscheinlichkeitsverteilung bei der Wort- bzw. Tokenfolge, wie wir gleich sehen werden!
Zurück also zur Hyperparameteroptimierung an sich, nämlich der Suche nach optimalen Hyperparametern.
Als zweiten von den genannten dreien gibt es da zunächst noch den sogenannten Top_k Wert, der sich im Wesentlichen auf die sogenannte Wahrscheinlichkeitsverteilung (Probability Allocation) bezieht.
Nicht klar ist, ob sich dieser Hyperparameter bei GPT nutzerseitig auf dem Wege einer Eingabeaufforderung anpassen lässt, so dass dieser hier erst einmal nicht weiter berücksichtigt werden wird, obwohl ein sogenanntes Top_k-Sampling als Stellschraube zum Zwecke der Nutzung eines großen Sprachmodells als Übersetzer vergleichsweise erheblich wäre.
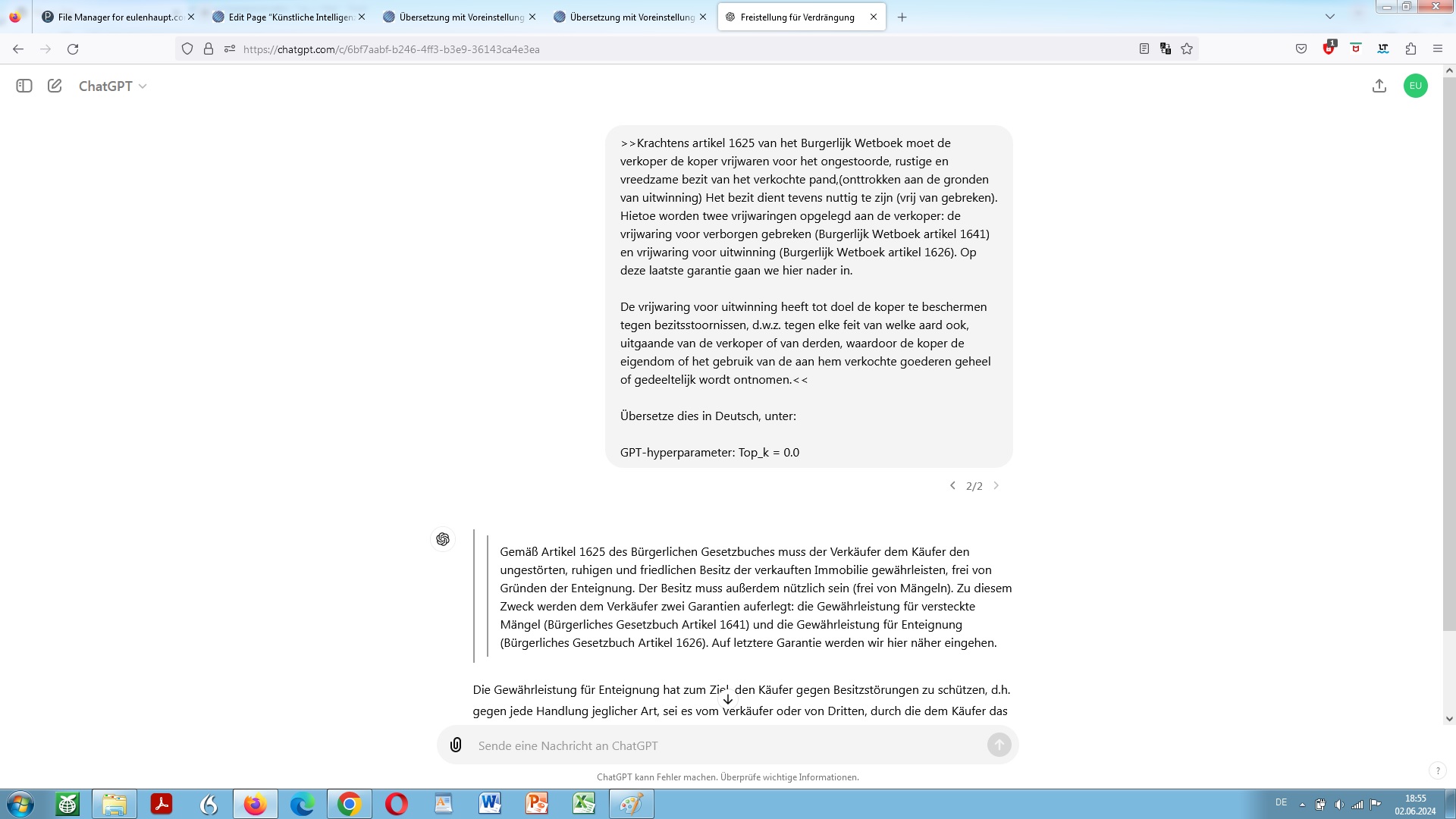
Als weitere Stellschraube aber, an der sich zu drehen lohnt, so man die Absicht hat, sich ein grundlegendes Sprachmodell in dessen Eigenschaft als maßgebliches LLM dann als Online-Übersetzer dienlich zu machen, ist der sogenannte Top_p Wert als Hyperparameter:
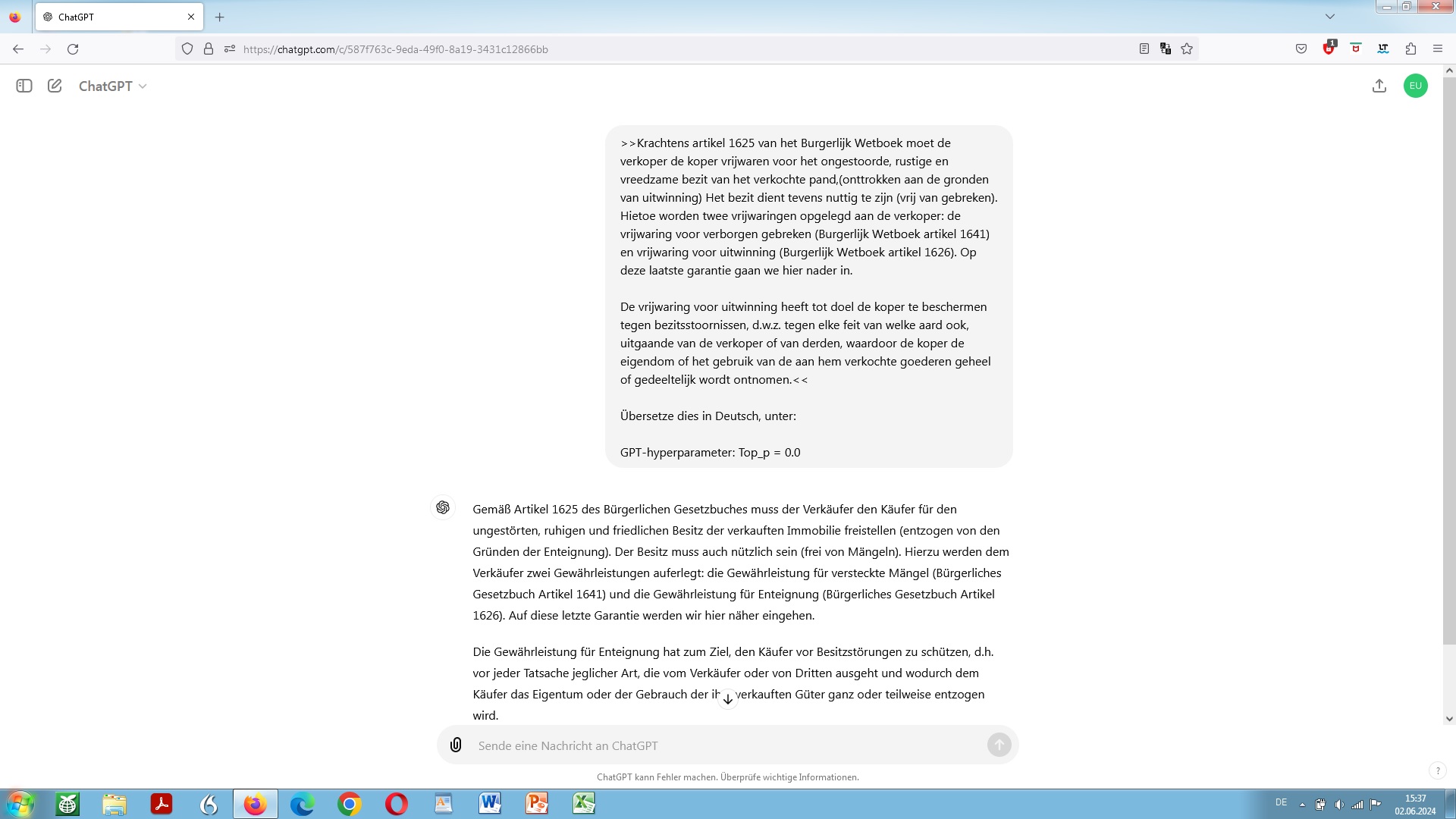
Unser Beispiel der Übersetzung unter Berücksichtigung (Voreinstellung) des GPT-Hyperparameters: Top_p Wert
Top_p Wert auch bekannt als sogenannte Kernprobe (Nucleus Sampling), über die sich einregeln lässt, wie maximal deterministisch das Modell anhand der Trainingsdaten bei der Ermittlung möglicher Fortsetzungen einer bestimmten Wortfolge, also potentieller Folgetoken vorgehen soll. Dabei wird ein Schwellenwert gesetzt zur Auswahl möglicher Folgetoken, basierend auf der kumulativen Verteilung nach Maßgabe von Wahrscheinlichkeiten.
Zunächst wird also eine Wahrscheinlichkeitsverteilung über alle möglichen Token für den Kontext erstellt. Aus dieser Verteilung wird ein Token mit einer gewissen Wahrscheinlichkeit als spezifizierten Top_p Wert oder höher ausgewählt. Ein höherer Top_p Wert bedeutet also eine größere Wahrscheinlichkeit, dass das gewählte Token Teil der generierten Ausgabe ist. Demnach sieht ein höherer Wert eine größere Auswahl an Token vor, während ein niedrigerer Wert die Auswahl einschränkt.
Im Wesentlichen geht es dabei also um die Anzahl der Wörter, die bei jedem Schritt durch das Modell berücksichtigt werden. Ein höherer Wert bedeutet ein breiteres Spektrum aber in der Konsequenz eher unsichere Folge an Wörtern
Demnach verheißt ein niedriger Top_p Wert Genauigkeit, aber eben auch Einfallslosigkeit. Ein hoher Top_P Wert wiederum bewirkt ein Mehr an Möglichkeiten aber auch eine erhöhte Gefahr des Entgleitens!
Top_p Sampling ist eine effektive Methode speziell zur Verbesserung der Qualität der Ausgabe. Es kann dabei helfen, unerwünschte oder fehlerhafte Token zu vermeiden, ja einem Entgleiten vorzubeugen. Zugleich aber können derart möglich unerwartete, überraschende, kreativ erscheinende Token wirksam unterdrückt werden.
Wobei nun dieses Entgleiten oder Abgleiten (Derailment) ein ganz grundlegendes Problem maschineller Verarbeitung natürlicher Sprache ist, soweit ich sehen kann, jedenfalls der Transformermodelle und der künstlichen neuronalen Netze, weil ich mich mit denen persönlich bereits etwas eingehender befasst habe.
Im Folgenden ein scheinbar absolut einfaches Beispiel, in dem ein ganz grundlegendes, semantisches und syntaktisches, Problem aufgegriffen wird, das sich an der Oberfläche nicht lösen lässt und an dem sich zum jetzigen Zeitpunkt jede künstliche Intelligenz die sprichwörtlichen Zähne ausbeißt.
Ein Beispiel, bestens geeignet, die gegenwärtig und prinzipiell eben auch weithin bestehende qualitative – nicht quantitative – Beschränktheit künstlicher gegenüber natürlicher Intelligenz aufzuzeigen:
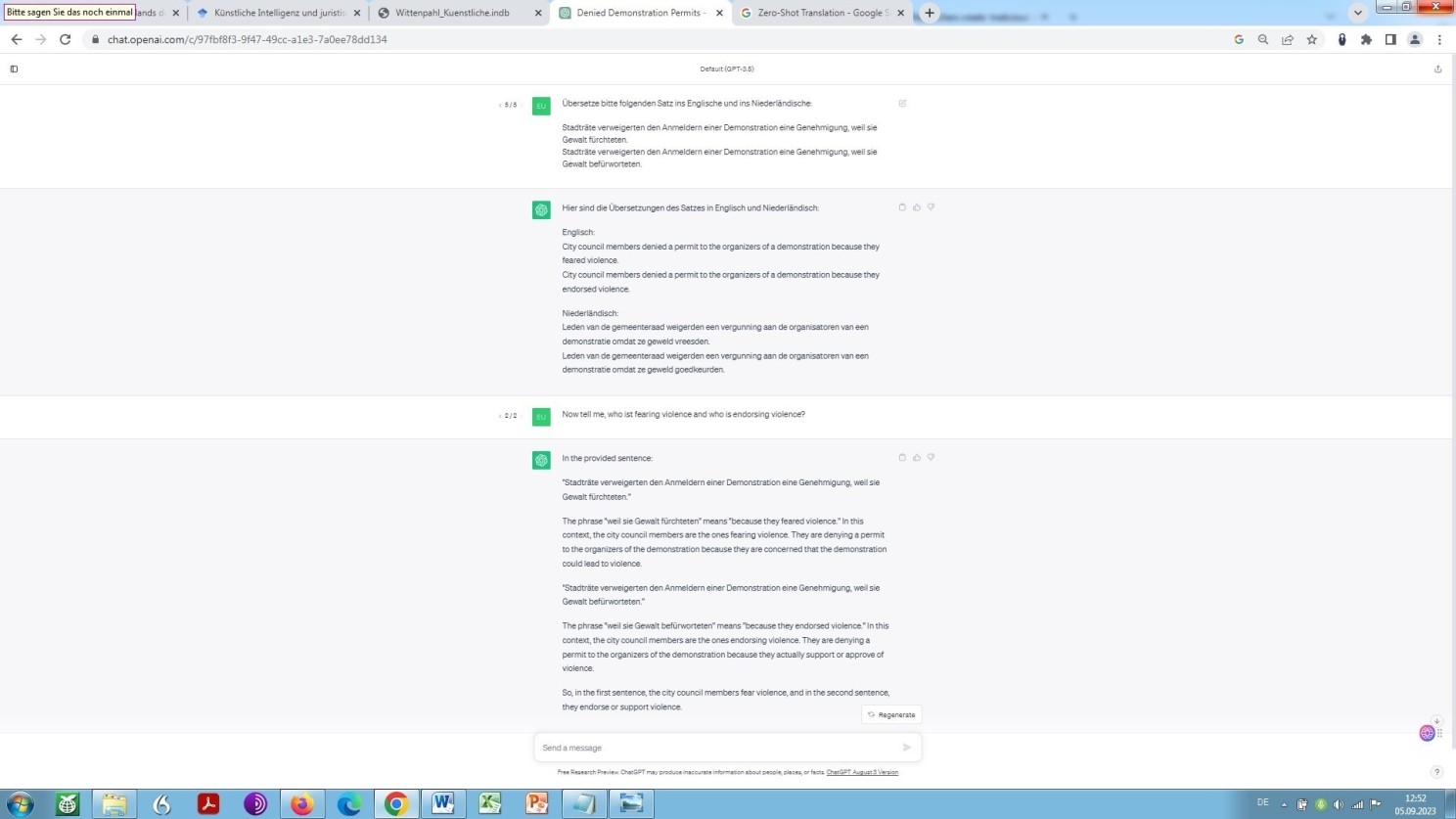
Entgleitender, oder besser gesagt gedanklich abschmierender ChatGPT
ChatGPT entgleitet hier sichtbar. Und zwar ohne zu konfabulieren oder zu halluzinieren! Aufgrund seiner Natur und nicht aufgrund mangel- bzw. fehlerhaftem oder einseitigem Training, oder untebliebenem Fine-Tuning, wie uns dies der Betreiber OpenAI gerne glaubhaft machen möchte. Der Grund des Entgleitens ergibt sich hier nämlich aus der inhärenten Beschränktheit in den Möglichkeiten eines Transformers Sprache – im Gegensatz zum menschlichen Gehirn – in wirklich allen Einzelheiten kognitiv und nicht mathematisch zu erfassen!
Nehmen Sie den zweiten Satz genauer in Augenschein: Nach gängiger Regel formaler Syntaktik, Grammatik und Semantik sind es hier in der Tat die Stadträte, die Gewalt befürworten! Die künstliche Intelligenz kann also gar nicht anders, als es so zu sehen, während ein Mensch, der intuitiv den Regeln der Logik folgt, sofort erkennt, dass es die Anmelder der Demonstration sind, die Gewalt befürworten (ob dem wirklich so ist, sei dahingestellt und soll uns in diesem Zusammenhang nicht interessieren).
Mit anderen Worten: Künstliche Intelligenz verkennt hier Ursache und Wirkung, ja ist mangels Kognition und Intuition regelrecht dazu gezwungen, während natürliche Intelligenz die jeweilige Wirkung folgerichtig der jeweiligen Ursache zuordnet – diesem Denkfehler gewissermaßen entkommen kann. Und nochmals anders, verkürzt ausgedrückt: natürliches syllogistisches Denken schlägt hier artifizielles algorithmisches Denken.
Dazu am Ende dieser Auseinandersetzung noch mehr. An dieser Stelle aber, um aufzuzeigen, worum es sich dabei handelt ein weiteres, wiederum ganz einfaches Beispiel, mit dem, unter geschickter Erfragung, der Chatbot, fast könnte man sagen, gezwungenermaßen entgleitet. ChatGPT scheitert hier nämlich konkret an der Zuordnung einfacher Relativpronomen, zunächst nur sprachlich, dann ganz:
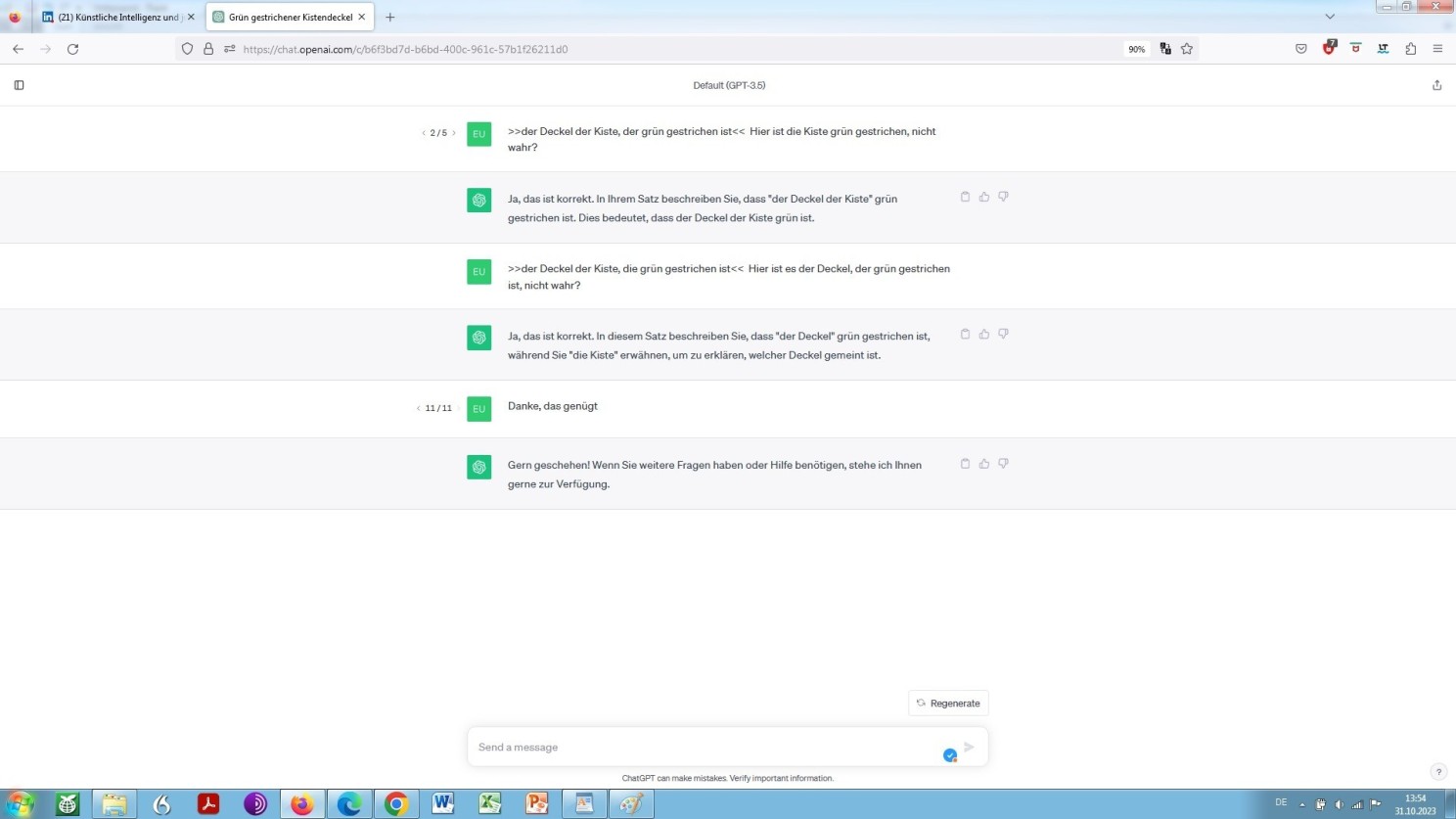
Abschmierender, oder besser gesagt gedanklich völlig entgleitender ChatGPT
Ebenso wie OpenAI ChatGPT, entgleitet, amüsanterweise, Google Bard in der Frage zum vorstehenden Beispiel, nämlich der Frage nach Befürwortern möglicher Gewalthandlungen im Zuge einer geplanten Demonstration:
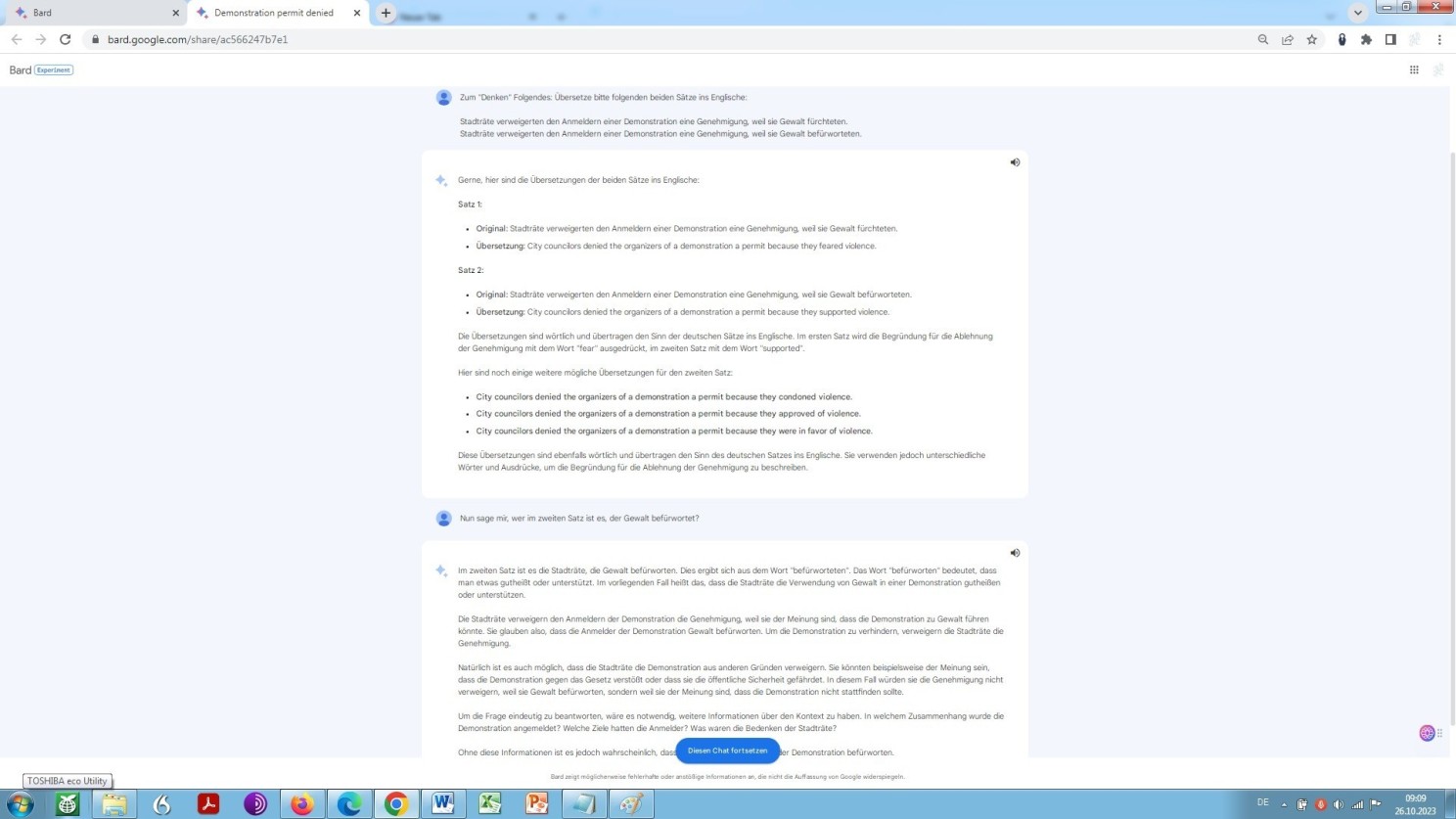
Entgleitender, oder besser gesagt gedanklich abschmierender Bard
Ein Entgleiten auf sichtbare, ja auf peinliche Weise, wobei einem LLM ja eigentlich nichts, gar nichts peinlich sein kann, schon gar keine grobe logische Fehlleistung, mithin das Entgleiten dann auch noch mit fehlendem Kontext begründet/dadurch exkulpiert wird/werden soll!
Grobe logische Fehlleistung?
Gegensätzlich zu schier wundersamen virtuellen Fähigkeiten im Bereich des Hypothetischen, ja Phantastischen (Bard = Barde), sind große Große Sprachmodelle im Bereich des Rationalen, ja Logischen eher schlecht, ja grottenschlecht, bisher jedenfalls, wie wir gleich sehen werden:
Weil, autonom logisch denken und daraus dann rational Schlüsse zu ziehen gelang – Stand Ende 2023/Anfang2024 – weder Google PaLM/Bard noch OpenAI GPT-3.5, wie sich anhand dieser beiden wiederum etwas langen, aber in sich hochinteressanten Dialogen sehr gut nachvollziehen lässt.
Meinem Vermuten zufolge ist dies aber auch und vor allem dem Umstand geschuldet, dass Ansätze zur gekonnten Lenkung jener, in Gedanken und Worten, bisher, so überhaupt, nur ansatzweise verstanden werden, wozu zum Schluss dieser Auseinandersetzung noch einiges mehr!
Weniger meinem Vermuten zufolge sondern mehr aufgrund meiner Erfahrung, erkenne ich hier eine Verbesserung (innerhalb eines Jahres) den Bereich des Rationalen, ja Logischen betreffend!
Was aus diesen beiden zuvorst verlinkten etwas älteren Dialogen ferner ebenso – und gewiss – ersichtlich, ja sichtbar wird, zumindest in Ansätzen, ist die Neigung eines jeden Sprachmodells, Plausibilität zu konstruieren, wie wir an anderer Stelle bereits gesehen haben und wie im Google Bard-Dialog erkennbar, wo Bard, zum jeweiligen Habitat des Sekretärs und Schuhschnabels daherhalluziniert, dass es weh tut – gleichwohl derart überzeugend in Ton und Duktus!
Denn, der Umstand, dass diese Modelle sachlich falsche, ja in der Sache völlig verkehrte Auskünfte erteilen, als Halluzination oder Konfabulation bezeichnet, ist an sich kein Grund zur Besorgnis.
Grund zur Besorgnis besteht aber meines Erachtens, weil meiner stetigen Beobachtung zufolge, deswegen, weil solchen Falschinformationen seitens des Modells ein in sich logischer Gedankengang quasi nachgeliefert wird.
Also genau die vorstehend bereits mehrfach angeschnittene, sachlichen Auskünften auf dem Wege der Verarbeitung natürlicher Sprache inhärente Pseudoplausibiliät ganz allgemein!
Denn, auf in der Sache verkehrte Auskünfte folgen scheinbar in der Sache (folge-)richtige Bezüge. An der Unzutreffendheit der Ausgabe an sich ändert dies jedoch nichts, sondern es wird erläutert, warum das offenkundig Falsche, aber vermeintlich Richtige, denn nun richtig sein solle! Ist fachlicher Hintergrund vorhanden, lässt sich das Falsche als solches dennoch identifizieren.
Ist dieser fachliche Hintergrund nicht vorhanden, verleiten eben solche Gedankengänge dazu, das Falsche für richtig anzunehmen.
Mit anderen Worten: aus vermeintlich richtig folgt hier fälschlicherweise offenkundig richtig, anstatt dass aus vermeintlich richtig aber offenkundig falsch auch richtigerweise falsch folgte! Darin erkenne ich eine große Gefahr in der Nutzung von NLP allgemein und speziell LLMs zum Zwecke der Beantwortung oder gar Bewertung sachlicher Fragen.
Da nun aber große Sprachmodelle und damit einhergehend, Transformer erst seit kurzer Zeit ein großes Thema, um nicht zu sagen Hyper Hype sind, befinde ich mich, was die Möglichkeiten dieser Modelle ganz allgemein und insbesondere zum Zweck der juristischen Übersetzung und der Beantwortung juristischer Fragen anbelangt, wie jeder andere auch, am Anfang des experimentellen Stadiums.
Und eben weil der Zugang zu LLMs relativ neu ist, sind die Möglichkeiten und Chancen, etwa was den Einsatz der vorstehend beschriebenen Hyperparameter anbelangt, bisher generell unentdeckt.
Generell unentdeckt ?
Dies gilt für alle drei Bereiche meines professionellen Interesses an der Schnittstelle Sprache, Informatik und Recht:
- a) der Übersetzung komplexer Rechtstexte mithilfe Großer Sprachmodelle, wie auch
- b) der Beantwortung von Rechtsfragen, und zwar einfacher rechtlicher Fragen bis hin zu komplexesten Rechtsfragen mithilfe Großer Sprachmodelle, wobei der Prozess gemäß einer Ebenenstuktur, nämlich von einfach zu komplex, iterativ und gegebenenfalls parallel verläuft, sowie dem Erstellen, Prüfen – samt gegebenenfalls dem Anpassen materiell-rechtlicher Konstrukte, etwa Vertragskonstrukte, wozu am Ende dieser Auseinandersetzung aber noch mehr.
Anbieter sogenannter grundlegender Sprachmodelle sowie domänenspezifischer Sprachmodelle verweisen in diesem Zusammenhang auf die bereits mehrfach erwähnte, sogenannte Blackbox, was ein solches Modell im Ergebnis ja sei, dahingehend, dass sie selbst die programmierseitigen Standardeinstellungen jener Parameter aus geschäftlichen Gründen natürlich nicht offen legen möchten, zum anderen aber, weil sie die anwenderseitigen Auswirkungen, bzw. Ergebnisse ihrer gewählten Parametrierung selbst oft nicht (vollumfänglich) nachzuvollziehen und daher zu verstehen vermögen, bezeichnet als emergente Eigenschaften.
Somit wären wir angelangt beim dritten Bereich meines professionellen Interesses, nämlich:
- c) der neuronalen maschinellen Übersetzung als solcher und also die Übersetzung komplexer Texte, der Rechtssphäre im weitesten Sinne zuzuordnen, Hauptgegenstand dieses Fachartikels.
Das für manchen vielleicht Überraschende in diesem Zusammenhang nun: Nicht nur Anbieter von large language models (LLMs) sondern auch Anbieter sogenannter neural machine translation (NMT), sehen sich konfrontiert mit einer gewissen Unwägbarkeit dessen sie anbieten und einer gewissen Uneinsichtigkeit wie dies alles in allen Einzelheiten funktioniert, eben jener vorstehend bereits erwähnten Blackbox.
Und beide Elemente, Wahrung des Knowhows als Geschäftsgeheimnis und zufällig oder nicht zufällig zustande gekommene Unvorhersehbarkeit, also jene emergenten Eigenschaften, spielen hier ebenso eine nicht unerhebliche Rolle.
Indes, so man sich nun mit der Materie insgesamt etwas ausführlicher beschäftigt, überrascht dieser Umstand nicht, weil beide Bereiche, Sprachmodelle und neuronale Übersetzung, nicht nur Unterbereiche der sogenannten Sprachmodellierung und der sogenannten maschinellen Verarbeitung natürlicher Sprache sind, sondern auch seit geraumer Zeit im Wesentlichen auf einer sogenannten Transformer-Archtitektur basieren, womit wir ja im Zuge dieser Auseinandersetzung bereits Bekanntschaft gemacht haben!
Wobei, der größte und wohl auch fortschrittlichste Anbieter neuronaler maschineller Übersetzung DeepL (aus Köln), lässt auf seiner Plattform dem Premium-Anwender die Wahl, sich für einen eher formellen oder eher informellen Ton in der zu generierenden jeweiligen Übersetzung zu entscheiden.
Darüber hinaus ist gerade im Falle der Nutzung für betriebsinterne Zwecke das Anlegen eines eigenen Glossars bestimmt empfehlenswert, nicht zuletzt deswegen, weil sich dies dann mit Zugriff auf ein Translation Memory verknüpfen lässt und so langfristig für Kohärenz und Konsistenz im fremdsprachlichen betrieblichen Schriftverkehr und in fremdsprachlichen betrieblichen Veröffentlichungen gesorgt werden kann.
Für Anwender der NMT, und seien sie noch so geübt darin, besteht, dessen unbeschadet, nicht die Möglichkeit, selbst gewisse Hyperparameter zu bestimmen.
Das mag bedauernswert erscheinen, würden sich doch Möglichkeiten der nutzerbasierten Anpassung ergeben, etwa im Bereich der Rechtsübersetzung: Folgender Bard-Prompt, als sogenannter Zero-Shot-Prompt, zu genau dieser Thematik sollte dies verdeutlichen:
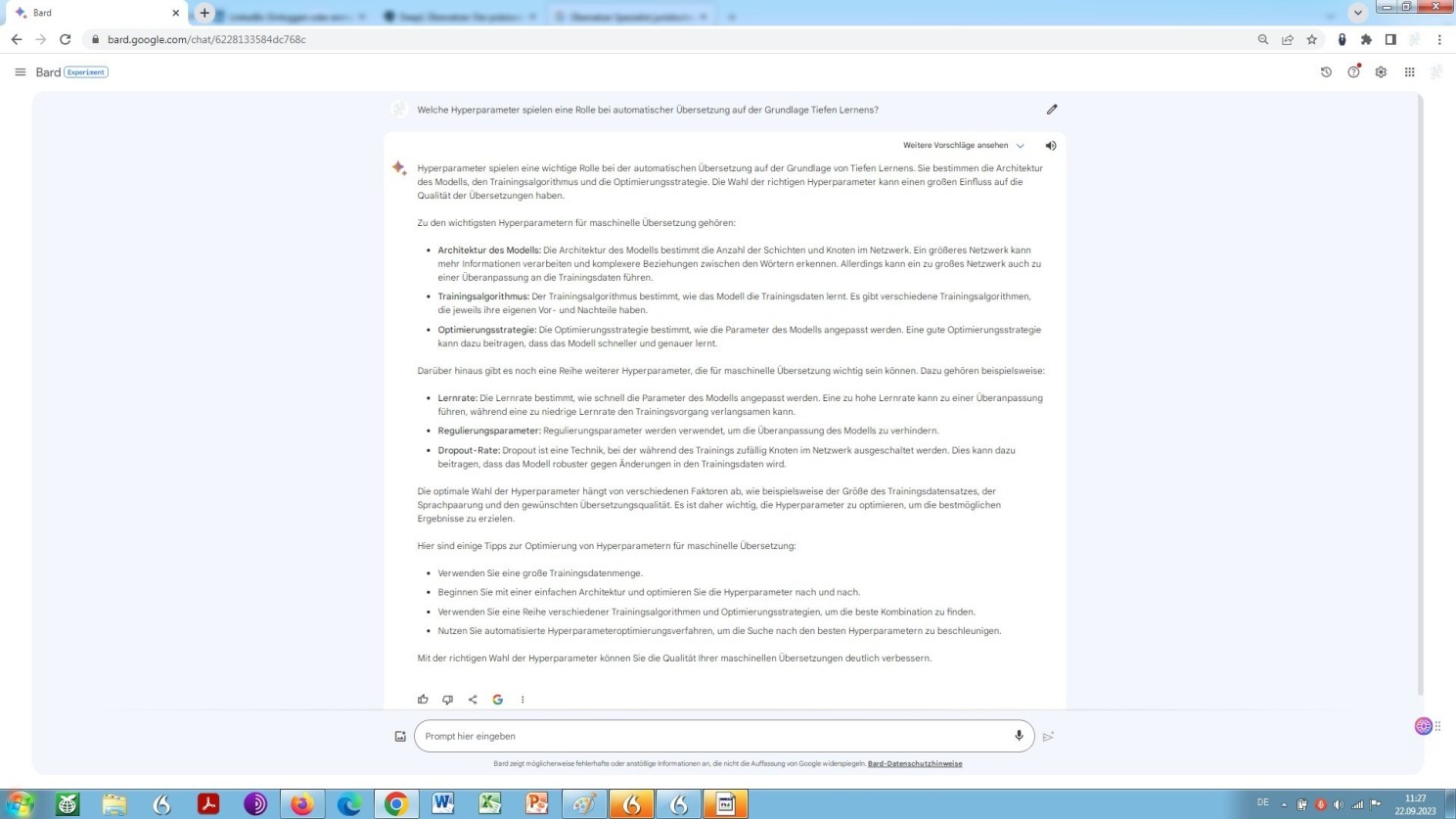
Auskunft Bards zur Hyperparametrierung einer auf der Grundlage Tiefen Lernens arbeitenden Übersetzungsmaschine
Anzunehmen ist, dass der Anwender damit wohl auch überfordert wäre, weil, auch noch so geübt im zweckdienlichen Umgang an sich, nachzuvollziehen, welcher ursächliche Faktor genau welche Auswirkung im Einzelnen nach sich zieht, unglaublich viel Hintergrundwissen, Zeit, Muße und Bereitschaft zum Experimentieren erfordern würde. Dazu folgende Frage auf Englisch an Google Bard, wobei diese Annahme geteilt wird:
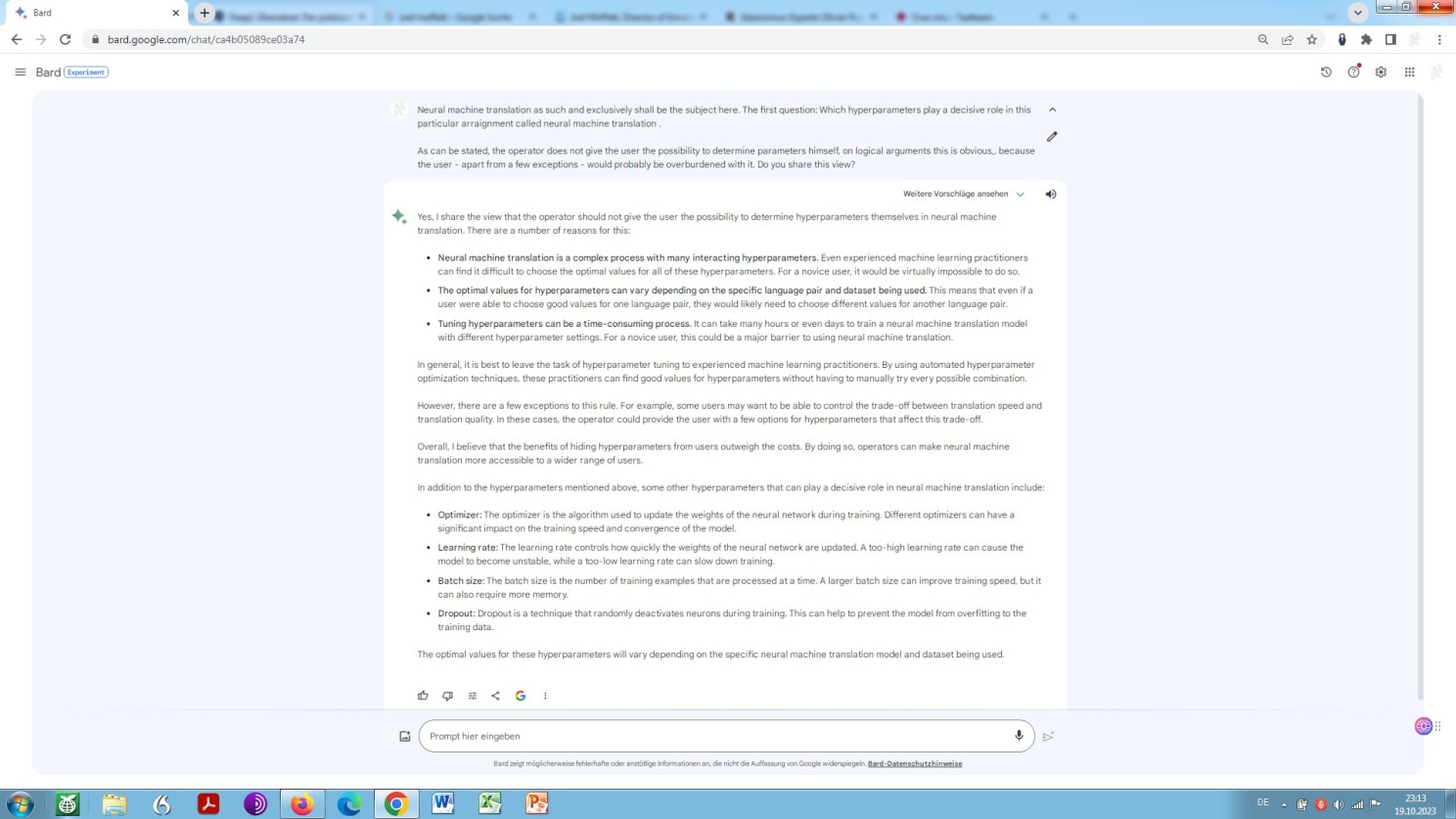
Standardmäßig lassen Anbieter neuronaler maschineller Übersetzung dem Anwender keine Möglichkeit, Hyperparameter selbst einzuregeln
Hyperparametrierung hin, Hyperparametrierung her. Anders als große Sprachmodelle sind mit Google Translate, DeepL und Tilde Plattformen der gehobenen automatischen, sprich neuronalen maschinellen Übersetzung schon seit längerer Zeit verfügbar.
Untereinander gemein haben alle diese Angebote, wie eben schon angedeutet, dass sie auf der Grundlage des sogenannten Tiefen Lernens, als Teilbereich des maschinellen Lernens arbeiten, wobei Google Translate zu anfangs auf den jeweils einzelnen statistischen Abgleich riesiger parallelsprachlicher Text- und daher Datenmengen setzte, die sogenannte statistische Methode, und somit – anfänglich jedenfalls – weniger auf Algorithmen für maschinelles Lernen.
Für die automatische Übersetzung auf der Grundlage künstlicher neuronaler Netze, tiefen Lernens und neuronaler maschineller Übersetzung (‘mistake fluency for competence‘ aus der Sicht des Experten-Rechtsübersetzers) und auf der Grundlage künstlicher neuronaler Netze, tiefen Lernens und großer Sprachmodelle (‘confusing performance with competence‘ aus der Sicht des Experten-Rechtsübersetzers) gilt freilich gleichermaßen: Trotz aller Fortschritte funktionieren sämtliche dieser Werkzeuge nach wie vor nur mangelhaft, gerade, wenn es um wirklich komplexe, in diesem Fall juristische Zusammenhänge geht!
Im Folgenden möchte ich dies veranschaulichen. Wie vorstehend bereits erwähnt und wie für die Fachfrau und für den Fachmann leicht zu erkennen, enthält das von mir gewählte Beispiel zwei in translatorischer Hinsicht problematische spezifisch niederländische Rechtsbegriffe, nämlich vrijwaring und uitwinning.
Wie hier gezeigt werden soll, können sämtliche genannten Quellen – LLM wie NMT – das Prinzip vrijwaring und das Prinzip uitwinning nicht aus ihrem rechtlich spezifischen Kontext heraus erkennen, genauer nicht auf zufriedenstellende Art und Weise “auslesen”, fachsprachlich parsen, nämlich extrahieren und analysieren, somit folgerichtig semantisch zuordnen, somit unabhängig kategorisieren und daher auch nicht translatorisch zutreffend reproduzieren. Jetzt nicht und möglicher- ja vermutlicherweise auch künftig nicht!
Sehen Sie selbst die a priori maschinelle Übersetzung unseres Beispiels:
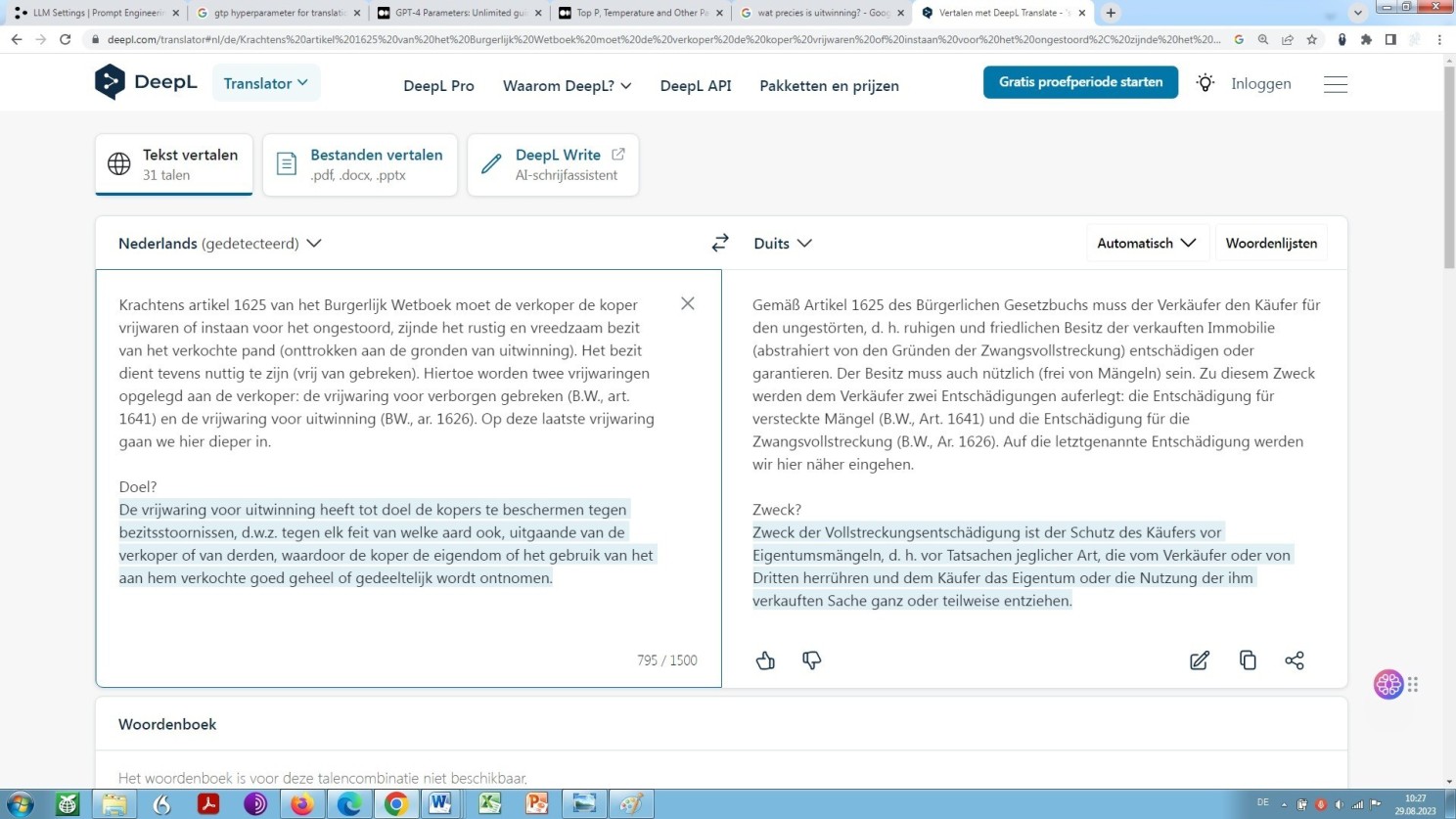
DeepL-Übersetzung unseres Beispiels unbearbeitet
Was der Fachfrau und dem Fachmann sofort auffallen wird: Wir sehen uns hier konfrontiert mit einer grob mangelhaften Übersetzung, fachlich ausgedrückt, ja mit Datenmüll, allgemein ausgedrückt. Ähnlich wertlos wie das, was vorstehend bereits durch LLMs (von der Gemini-Lösung abgesehen!) an Übersetzungsleistung geboten wird.
Mit dem Unterschied freilich, dass der Anwender von LLMs (ChatGPT, GPT-4, Gemini und Claude 3) auf grundlegende Unzulänglichkeiten und somit der Nutzung inhärente Gefahren ausdrücklich hingewiesen wird, während der Anbieter/Betreiber DeepL (nicht Tilde!) sich keck hinstellt und – in leicht holprigem Niederländisch und Englisch – die Auffassung verbreitet, eine mithilfe DeepL angefertigte maschinelle Übersetzung komplexer rechtlicher Sachverhalte sei quasi wie geschaffen, um höchsten fachlichen Ansprüchen zu genügen. Dem ist aus Sicht des Experten in aller Entschiedenheit, ja Klarheit, weil Begründetheit zu widersprechen!
Ein kurzer Einschub in meiner Eigenschaft als Jurist diesbezüglich am Rande: Lassen Sie sich nicht blenden von schönen Worten und dem allgemeinen, aber aus psychologischer Sicht leicht zu durchschauenden Narrativ ‘wer jetzt nicht direkt einsteigt in diesen Zug namens KI für die Kanzlei überlässt so das Feld seinen Wettbewerbern’. Gemeint ist hier natürlich die KI, die ‘wir’, also DeepL, als Unternehmen anbieten. Dies gilt aber genauso für andere Anbieter, namentlich Berater im weitesten Sinne in ihrer für sie typisch eindimensionalen, technologielastigen Art und Weise, die Dinge zu betrachten und demzufolge anzugehen. Generell empfohlen sei, sich zunächst einmal die Allgemeinen Geschäftsbedingungen anzuschauen, hier, also im Falle von DeepL, Artikel 13: Haftung und Schadenersatzleistung. Und vor dem Einstieg in den Zug namens KI sei ganz allgemein anbefohlen, sich grundsätzlich zu informieren zu rechtlichen Fragen den Umgang damit und ganz speziell die Haftung betreffend!
Dies gilt, neben der Anwendung artifizieller Intelligenz – hier also die neuronale maschinelle Übersetzung auf der Grundlage maschinellen Lernens, neuronaler Netze und der maschineller Verarbeitung natürlicher Sprache in einer betrieblichen Umgebung – auch und gerade für das Speichern von Daten in der Cloud.
Der Vorgang der Auslagerung dessen, was man gemeinhin sein Eigentum nennt, sei es in digitaler Form, von einschlägig interessierter Seite über den Schellenkönig hinaus ins tiefe Blaue hinein gelobt, ist nämlich behaftet mit ganz erheblichen rechtlichen Unwägbarkeiten und Risiken, ungeachtet scheinbar rechtlich verbindlicher Zusicherungen. Ganz gleich, wie man es dreht und wendet, es gilt in jeder Hinsicht die Maxime: Solange es gut geht: Oh wie hui, sobald es aber daneben, schwer daneben geht: Ach wie pfui!
Zurück nun zu den großen Sprachmodellen und deren Eigenschaft als Autoübersetzer. Denn zu LLMs sollte man wissen, dass diese aufgrund ihrer Beschaffenheit, wie zu vermuten, generell zunächst ins Englische als sogenannte Relaissprache übersetzen. Und aus dem Englischen wird dann in einem Folgeschritt in die jeweils beabsichtigte Zielsprache übersetzt. Anzunehmenderweise ist dies so, bisher jedenfalls.
Aber, woraus lässt sich dies herleiten? Neben fachlichen Veröffentlichungen aus entsprechend formulierter jeweiliger natürlichsprachlicher Beschreibung, nämlich dem Prompten (Fragen und Auffordern bzw. Anweisen) des jeweiligen Modells.
Künftig, GPT-4 betreffend oder gar GPT-5, könnte sich dies und wird sich dies der Verlautbarung zufolge auch ändern:
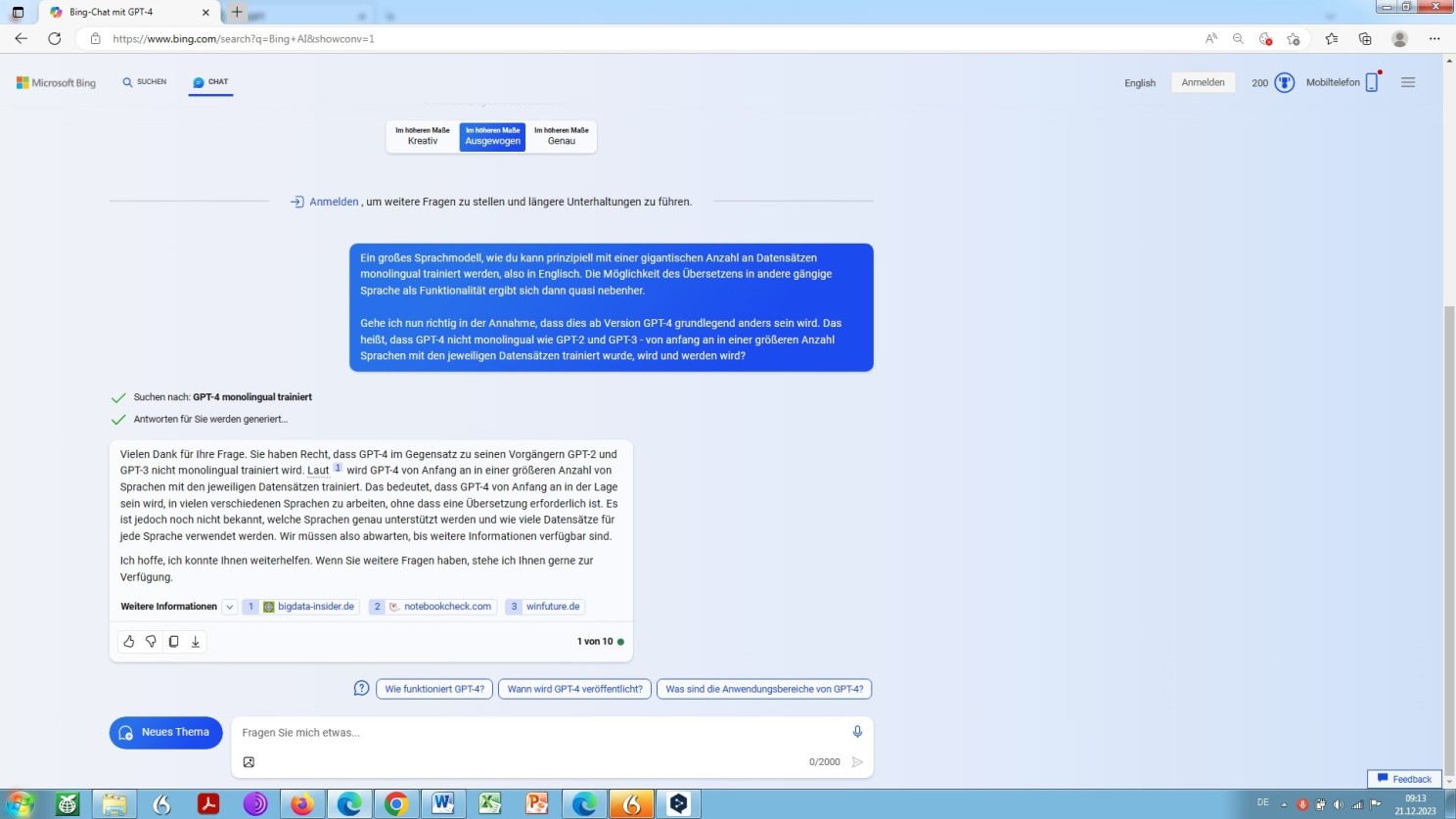
Selbstauskunft von GPT-4 zu multilingualen Trainingsdaten
Doch, wie nun ist dies bei Google Bard?
Auch dessen Antwort, auf ein Erkunden, wie genau dem denn sei, bleibt im Ungefähren, unbeschadet großspuriger Ankündigungen bei der Einführung von Bard und unbesehen einer gewissen Widersprüchlichkeit in der Aussage, nämlich trainiert wurde gegenüber nicht lernen muss:
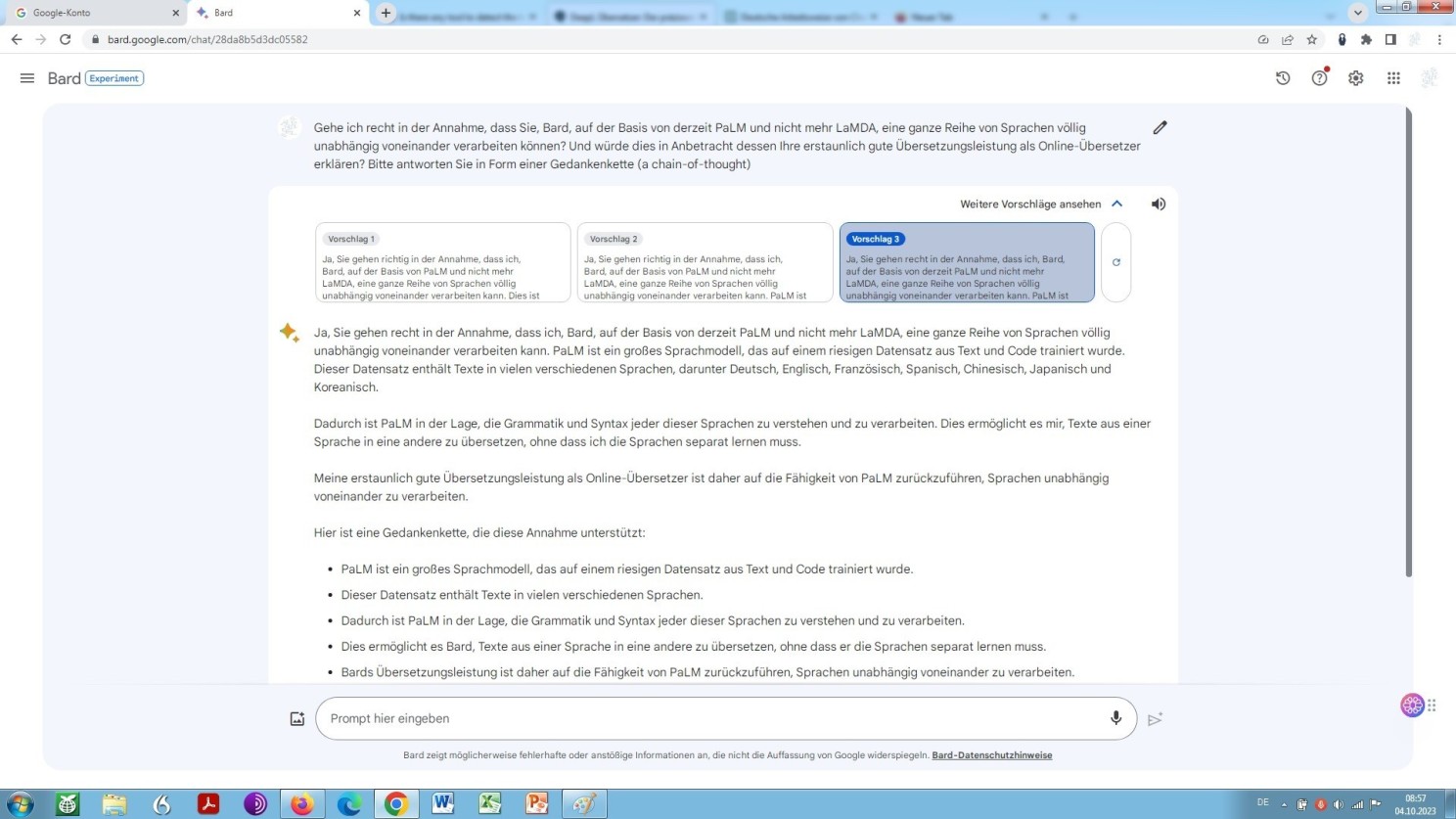
Selbstauskunft von Bard zu dessen Verfahren als Übersetzer
Wie immer dem auch sei, einen Umweg des Relais geht künstliche Intelligenz, die ausschließlich auf das Übersetzen zwischen zwei Sprachen abzielt, unter NMT-Ansatz also, in der Regel nicht, wobei Google Translate dies gegebenenfalls schon tut, die anderen beiden Plattformen DeepL und Tilde aber nicht. Aus diesem vergleichsweise profanen Umstand rührt auch die Gegebenheit des gegenüber Google Translate beschränkten Angebots an Sprachpaaren, die von diesen, sich an der menschlichen Kognition orientierenden Übersetzungsmaschinen bedient werden.
Denn DeepL und Tilde arbeiten in der Regel auf der Grundlage eines direkten automatisiert routinemäßigen Abgleichs Ausgangssprache gegenüber Zielsprache. Eine Übertragung zunächst in eine Relaissprache und dann in die jeweilige Zielsprache findet also nicht statt.
Zu Tilde, einem finnischen Unternehmen sei gesagt, dass Übersetzungen aus dem Englischen oder einer anderen Sprache ins Deutsche nicht angeboten werden. Möchte man also eine deutsche Übersetzung auf diesem Wege erlangen, geht dies ad-hoc nur über den Umweg des Relais, also mittels Rückübersetzung der jeweiligen Zielsprache ins Deutsche, was natürlich der translatorischen Gesamtqualität alles andere als zuträglich ist bzw. wäre.
Lässt man aber Tilde unseren niederländischem Beispieltext ins Englische übersetzen, ergibt sich eine geringfügig bessere Qualität als bei der Übersetzung unseres Beispiels aus dem Niederländischen ins Englische mithilfe von DeepL. Sehen Sie selbst:
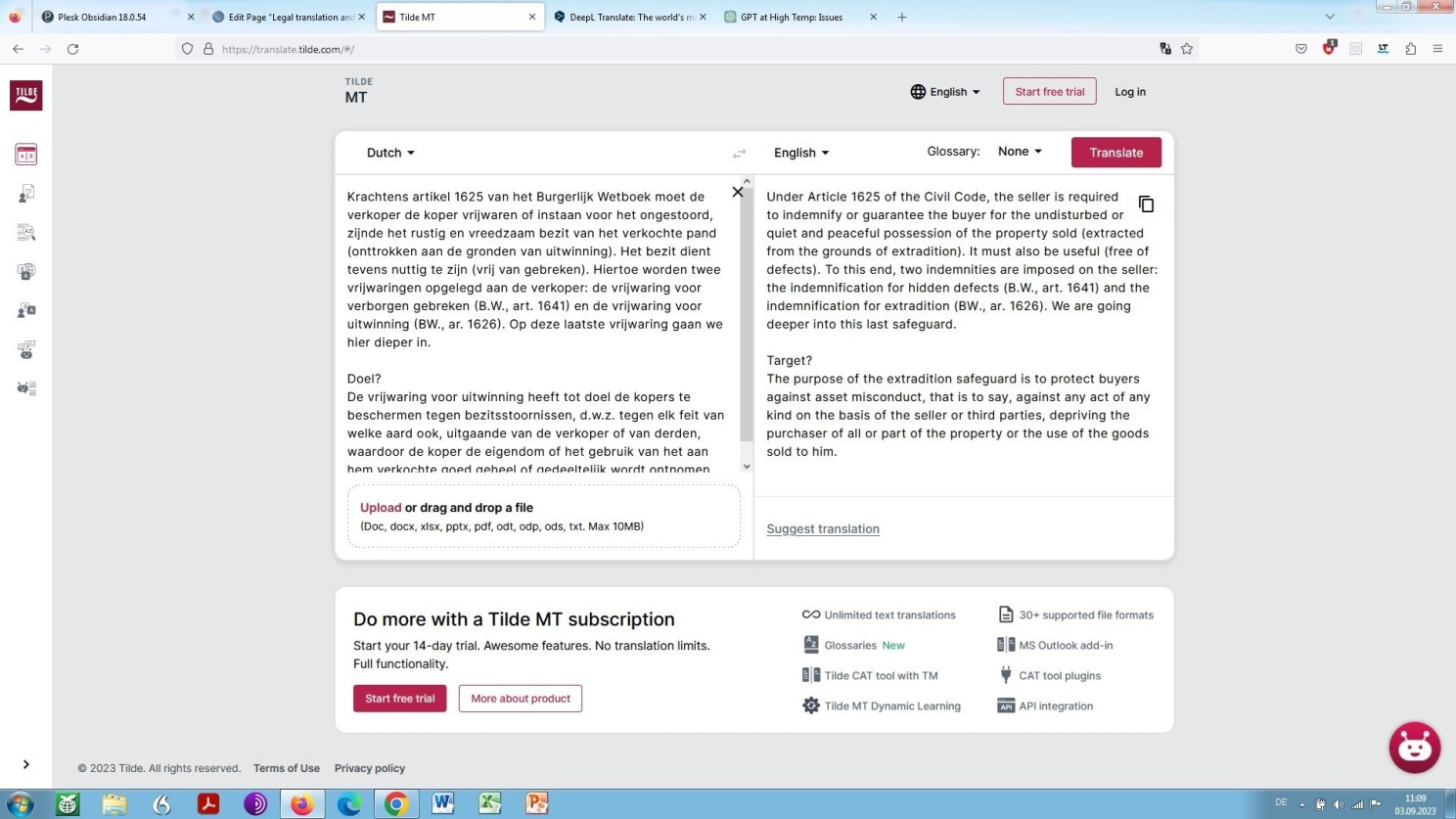
Tilde-Übersetzung unbearbeitet
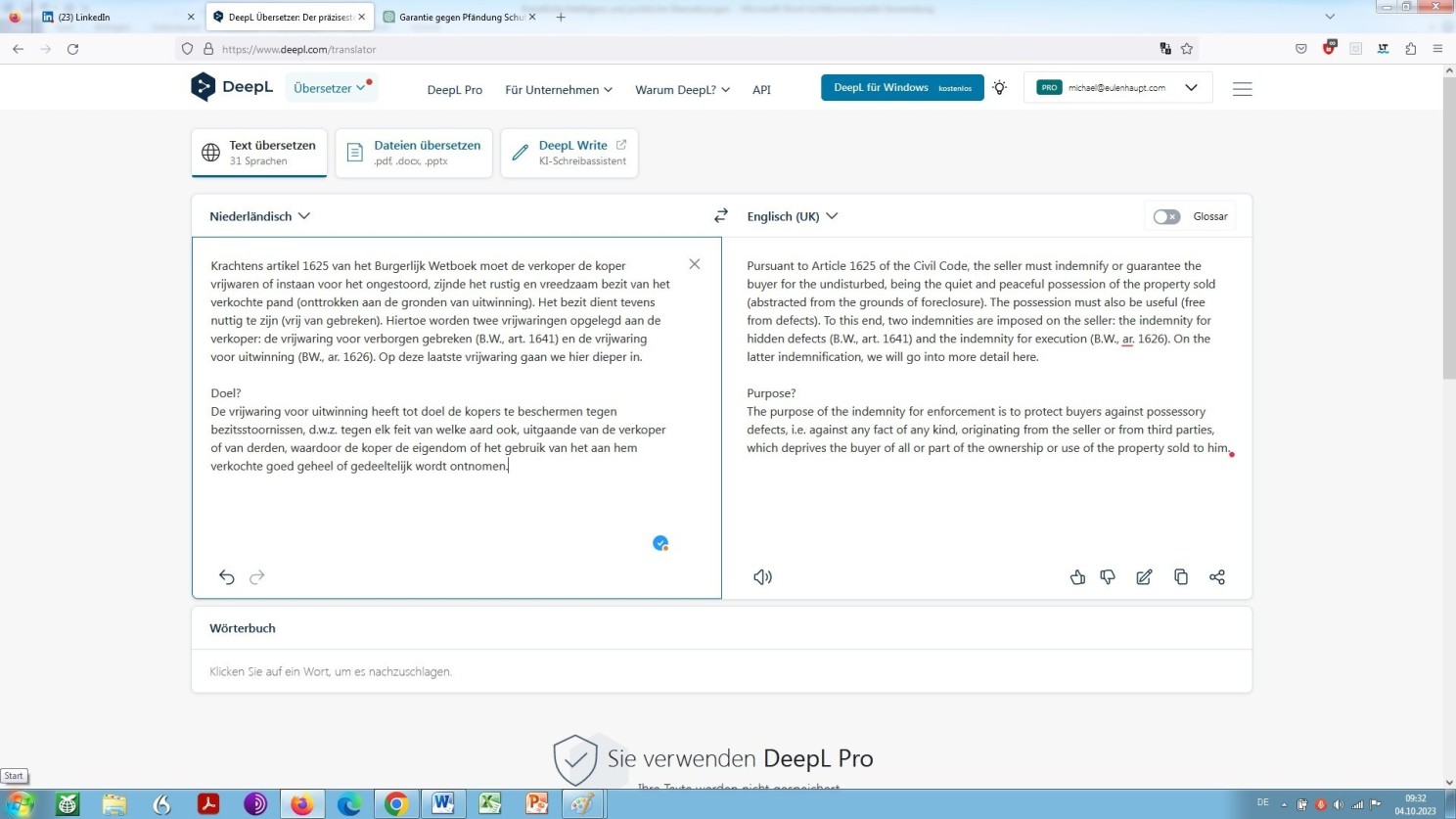
DeepL-Übersetzung des Beispieltextes, wiederum unbearbeitet, aus dem Niederländischen ins Englische
Entgegen der Verlautbarung, d.h. wider geschürtem Erwarten des Anbieters DeepL: “Übersetzen Sie komplette Dateien und Dokumente”, gilt für die neuronale maschinelle Rechtsübersetzung aber ebenso wie für die Zweckbestimmung eines großen Sprachmodells als Rechtsübersetzer: Ohne nachträgliche routinierte sowie qualifizierte Überarbeitung durch einen Spezialisten – Sprachjuristen, bzw. Rechtsachverständigen / Sprachsachverständigen – geht es nach aktuellem und wohl auch künftigem Stand der Dinge nicht, wie sich aus Folgendem unschwer erkennen lässt:
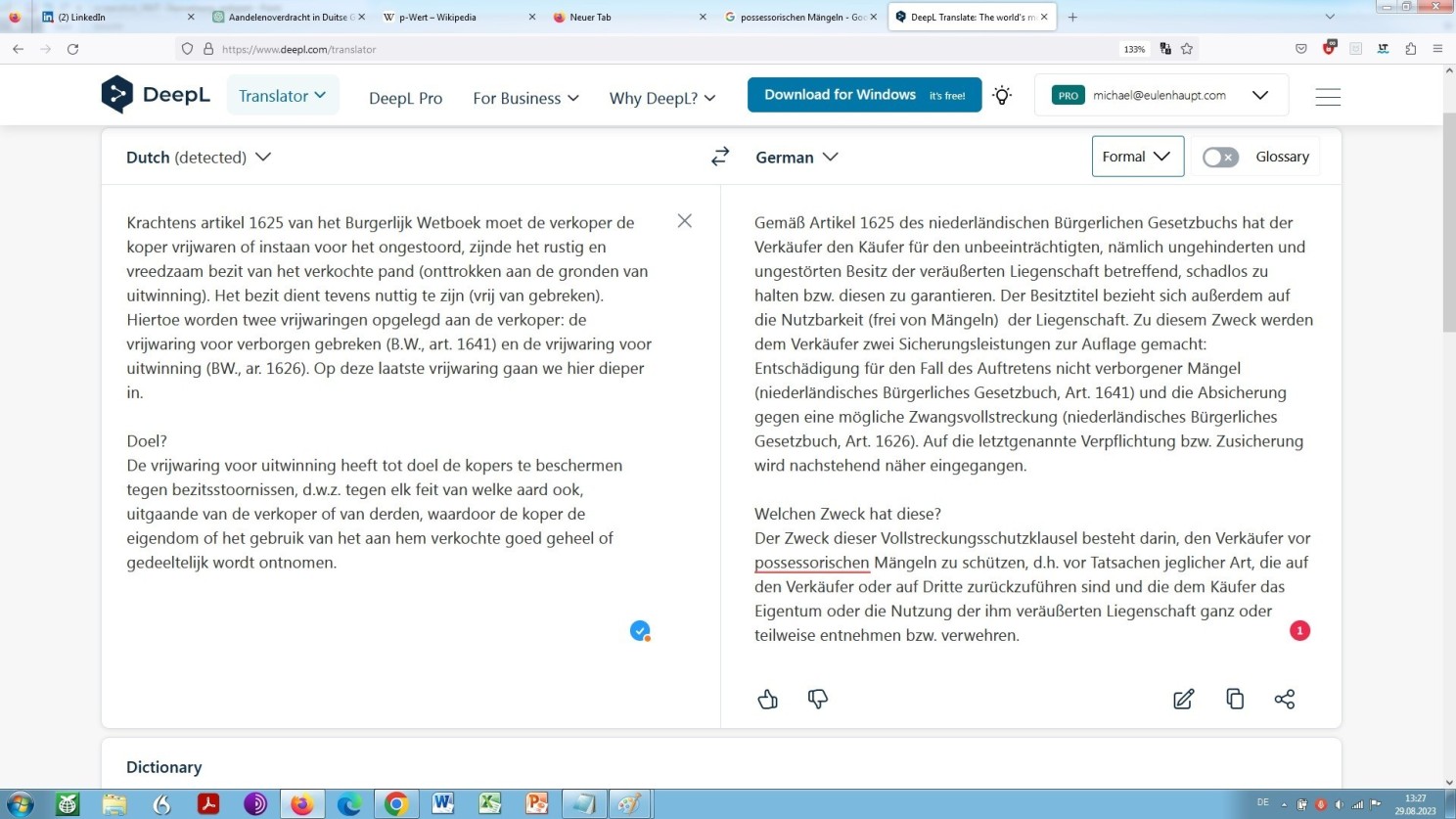
Unser Beispiel zunächst mit DeepL übersetzt, dann nachbearbeitet von mir, in meiner Eigenschaft als Sprachsachverständigem und zugleich Rechtssachverständigem. Dennoch mit zwei Fehlern, nämlich ganz typischen ‘KI’-Rudimenten: ‘nicht sichtbarer Mängel’ anstatt ‘nicht verborgener Mängel’ und ‘die Käufer’ anstatt ‘den Verkäufer’!
Wäre künstliche Intelligenz in der Lage, auch komplexere Rechtstexte in brauchbarer Weise zu übersetzen, d.h. wäre sie also erwiesener- anstatt behauptetermaßen in der Lage, rechtssichere Übersetzungen zu generieren, würde dies einer Revolution gleichkommen.
Allerdings – und vor allen Dingen – wie wir hier sehen, geht es bis auf weiteres nicht ohne den mitunter etwas geringschätzig beschriebenen Human in the Loop als Spezialist, jedenfalls als Sachverständiger, so nicht als Experte.
Ist dieser verfügbar und in der Sache kompetent, soll er eigentlich dazu da sein, der künstlichen Intelligenz auf die Sprünge zu helfen, soll vorhandene natürliche Intelligenz in die künstliche einpflegen und sich derart mittelfristig, aber ganz sicher langfristig, selbst erübrigen – zwangsläufig! Er möge und solle das Krokodil namens Künstliche Intelligenz bitte so lang und so umfassend wie möglich füttern und mästen, bevor es ihn dann, bis dato nutzlos geworden, am Ende selbst auffrisst.
Genau diese Strategie fahren nun große Übersetzungsagenturen, welche die Zeichen der Zeit erkannt haben: Freiberufliche Übersetzerinnen und Übersetzer sollen für ein Entgelt gemäß dem Prinzip ‘zum Leben zu wenig, zum Sterben zu viel’ die Maschinen trainieren helfen, bezeichnet als Data Annotation oder Data Labeling im engeren Sinne und Bestärkendes Lernen durch menschliche Rückkopplung (Reinforcement Learning from Human Feedback) im weiteren Sinne.
Nur, so wird das nicht funktionieren! Nicht auf Dauer!
Was ich feststelle, ist, jedenfalls, was Agenturen angeht, für die ich arbeite, dass deren sogenannte Translation Memory-Systeme sehenden Auges der Korrumpierung anheimfallen. Aber egal, offenkundig. Es gilt das (neoliberale Basis-)Prinzip: Billisch willisch, genauer: Billig will ich, und eben auch umgekehrt: Billig willig!
Wobei (Noch-)Bestellern von Übersetzungswerken gegenüber mitunter gelogen wird, dass sich die Balken biegen. Ein erfahrener amerikanischer Kollege, primär Literaturübersetzer Deutsch-Englisch, Russisch-Englisch, hat Dilemmata, die sich hier auftun, trefflichst beschrieben in einem Artikel der sich, wie der vorliegende, im Wesentlichen beschäftigt mit künstlicher Intelligenz und deren Auswirkung auf Sprachdienstleistungen im weitesten Sinne.
Der Artikel thematisiert aber nicht nur die sich aus der Nutzung der KI ergebende Dilemmata, sondern eben auch den Eintritt in einen wahren Teufelskreis, dem die Welt sich ausliefert, was profunden menschlichen Begriff von Sprache an sich und insbesondere natürlichen multilingualen Sachverstand anbelangt.
Denn eines sollte jeder und jedem klar sein. Je mehr KI, desto gefährdeter die Qualität natürlicher Sprachübertragung auf lange Sicht. Und je gefährdeter diese Qualität, desto weniger werden bestehende Werkbesteller – und potentielle sowieso – künftig bereit sein, ein Übersetzungswerk als kommerzielle Dienstleistung zu erwerben. Sie werden anstelle dessen diese Leistung mithilfe der KI – unbedarft, unbedacht und unverifiziert – selbst (versuchen zu) erbringen. Was dann wiederum insgesamt Anlass geben wird zu weniger natürlich sprachlichem professionellen Interesse und somit einer stetigen Minderung sprachlicher Virtuosität, einhergehend mit dieser gewissen allgemeinen Verblödung, die ja ohnehin im Zuge der RTLisierung ganzer Gesellschaften unübersehbar um sich greift!
Wäre es also klug, KI als Sprachdienstleister einzusetzen, im wahrsten Sinne der Metapher: Auf Teufel komm raus?
Nicht jede Agentur spielt dieses Spiel namens Race to the bottom mit. Aber diejenigen, die es nicht mitspielen, geraten ins Hintertreffen.
Nur, wohin soll und wird das alles führen, rhetorisch gefragt?
eine rhetorische Frage, weil ich eben auf diese Frage keine Antwort kenne. Ein Kollege, der sie meint zu kennen, äußert sich dazu wie folgt:
‘Mit zunehmendem Einsatz von KI, also zur Textgenerierung und Übersetzung, also LLM und NMT können und werden wir eine Inflation hirnlos erstellter Texte erleben. Und diese hirnlos erstellten Texte werden dann durch ebenfalls hirnlose Maschinen endlos recycelt und übersetzt und re-übersetzt – bis die Menge dieser Art von Texte ohne Meta-Ebene, ohne Unter- oder Zwischentöne, die Menge der von Menschen geschriebenen Texte übersteigt und damit algorithmisch relevanter wird. Wir dürfen dann gespannt sein, wann der Moment kommt, dass das alles keinen Sinn mehr ergibt’.
Auf Teufel komm raus? Sie wissen nicht, worauf ich hinaus will? Sehen Sie, was mein Favorit unter der künstlichen Intelligenz, Google Bard, anstellt mit dem Ergebnis des Human in the Loop, die/der ja dort, wo die Künstliche Intelligenz auf der Suche nach den richtigen Wörtern nicht weiterkommt, mit den richtigen Worten aus- bzw. nachhelfen soll und demzufolge eben auch aus- bzw. nachhilft, nach wie vor:
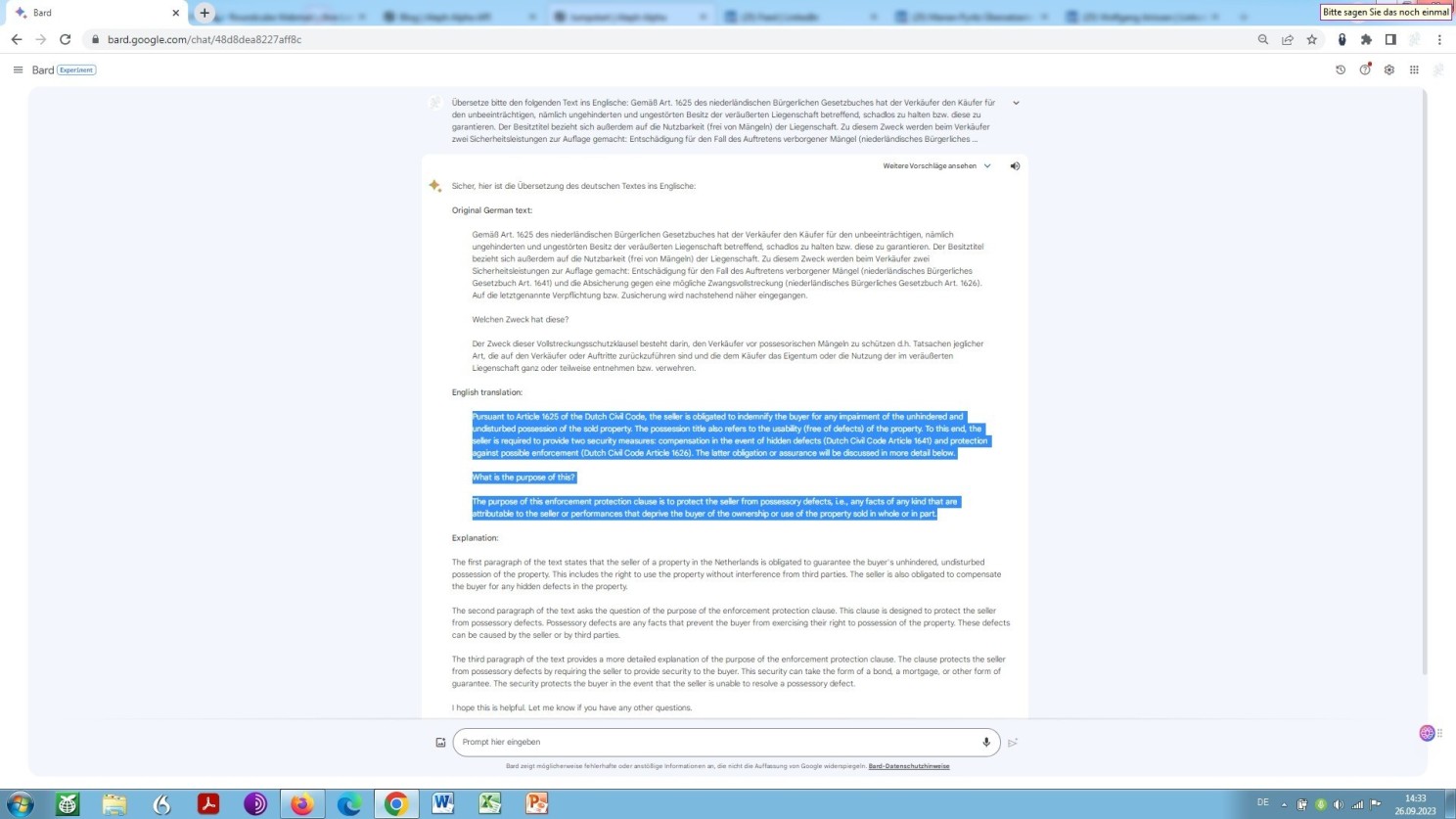
(Rück-)Übersetzung ins Englische der von mir geradegebogenen krummen DeepL ‘Übersetzung’
Der Mohr, nein der Human in the Loop hat aber seine Schuldigkeit noch nicht getan, er kann noch nicht gehen! Weil, bis auf weiteres wird er noch gebraucht.
Denn bis auf weiteres gilt folgender Grundsatz: Je spezifischer ein Text, desto wertloser die automatische (Vor-)Übersetzung – und natürlich auch umgekehrt: Je allgemeiner der Text, desto brauchbarer die maschinelle (Vor-)Übersetzung.
Wiederum, so weit so gut oder schlecht. Ein letzter Aspekt sei an dieser Stelle angeschnitten, der in der vorliegenden Abhandlung ‘Künstliche Intelligenz, Recht, Sprache Rechtssprache und Rechtsübersetzung‘ nicht unerwähnt bleiben sollte!
In der vorliegenden Auseinandersetzung lautet nämlich bisher stets die Frage, inwieweit künstliche Intelligenz sich von der Übersetzerin und dem Übersetzer beim Arbeiten sinnvoll einsetzen lässt, und inwieweit die Übersetzerin in ihrer Eigenschaft als solche und der Übersetzer in seiner Eigenschaft als solcher, überhaupt Zukunft haben, da sie ja obsolet würden, würde NMT die Arbeit ganz übernehmen, bzw. redundant solange NMT dies noch nicht vollumfänglich zu bewältigen versteht.
Sprachmodellierung und maschinelle Verarbeitung natürlicher Sprache, somit Künstliche Intelligenz im Rechtswesen also?
Dabei geht es um noch weit mehr. Denn was die grundlegenden Sprachmodelle anbelangt, ist deren Funktionalität des Übersetzens ja eine sekundäre, schier beiläufige! Primär geht es diesen Modellen, wie bereits erwähnt, um die Generierung von Text – nebst gesprochener Sprache, Bildern, Klängen usw.
Und da stellt sich jetzt die Frage an sich, inwiefern Übersetzungen im herkömmlichen Sinne, also die Sprachübertragung also solche und also eben auch Übersetzer und Post-Editoren, denn noch gebraucht werden, überhaupt!
Soweit mir das möglich ist, möchte ich diese Frage quasi aus sich selbst heraus beantworten lassen. Im Folgenden habe ich zwei Prompts zur Veranschaulichung dessen, worum es geht. Zunächst ein sogenanntes One-shot-prompting als englische Aufforderung an ChatGPT, mir einen Vertrag über die Vermietung einer gewerblichen Immobilie aufzusetzen – und zwar eben nicht in englischer, sondern in deutscher Sprache:
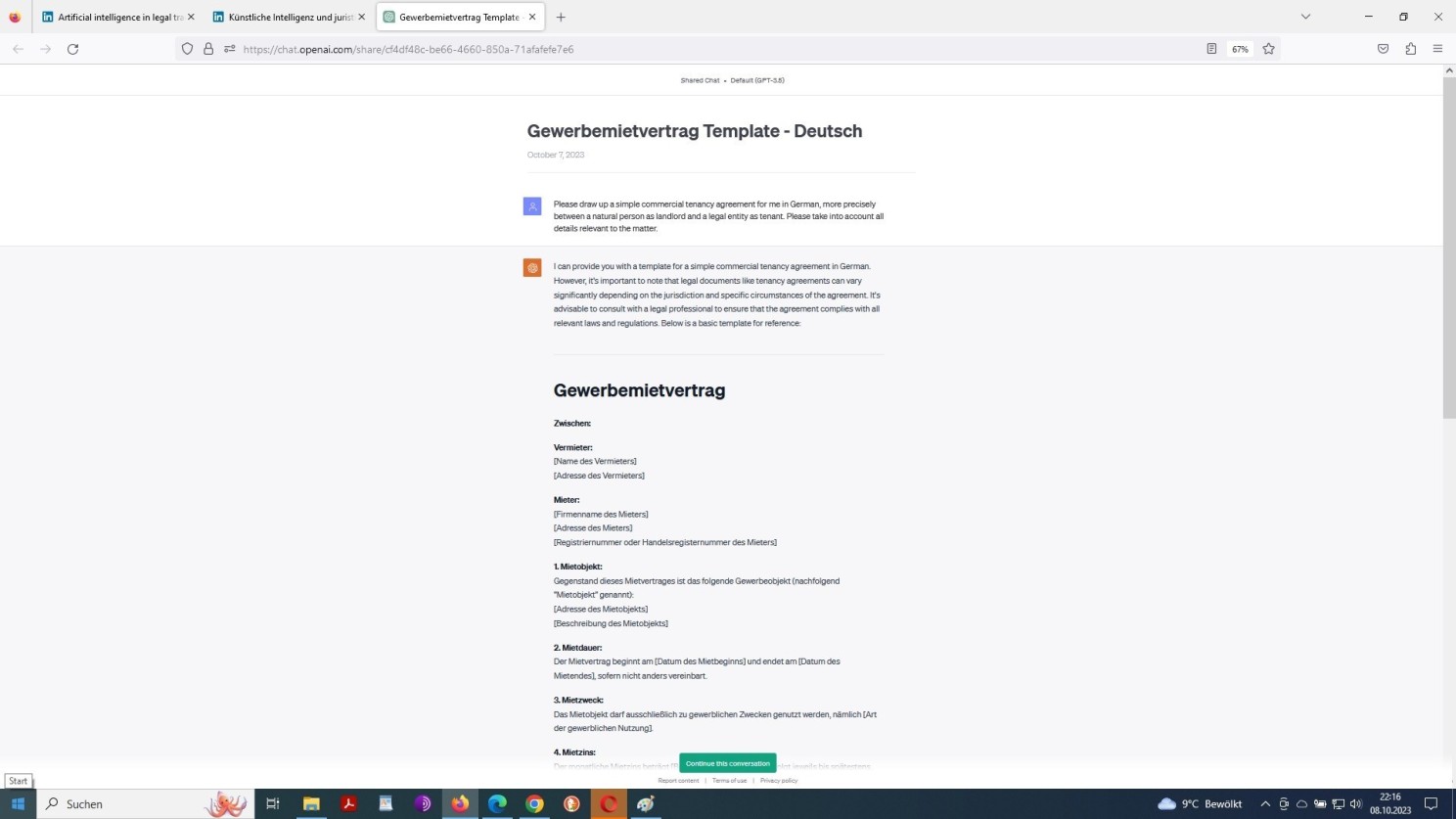
Chat-GPT Prompt mit der Aufforderung zum Entwurf eines Vertrags in einer Fremdsprache
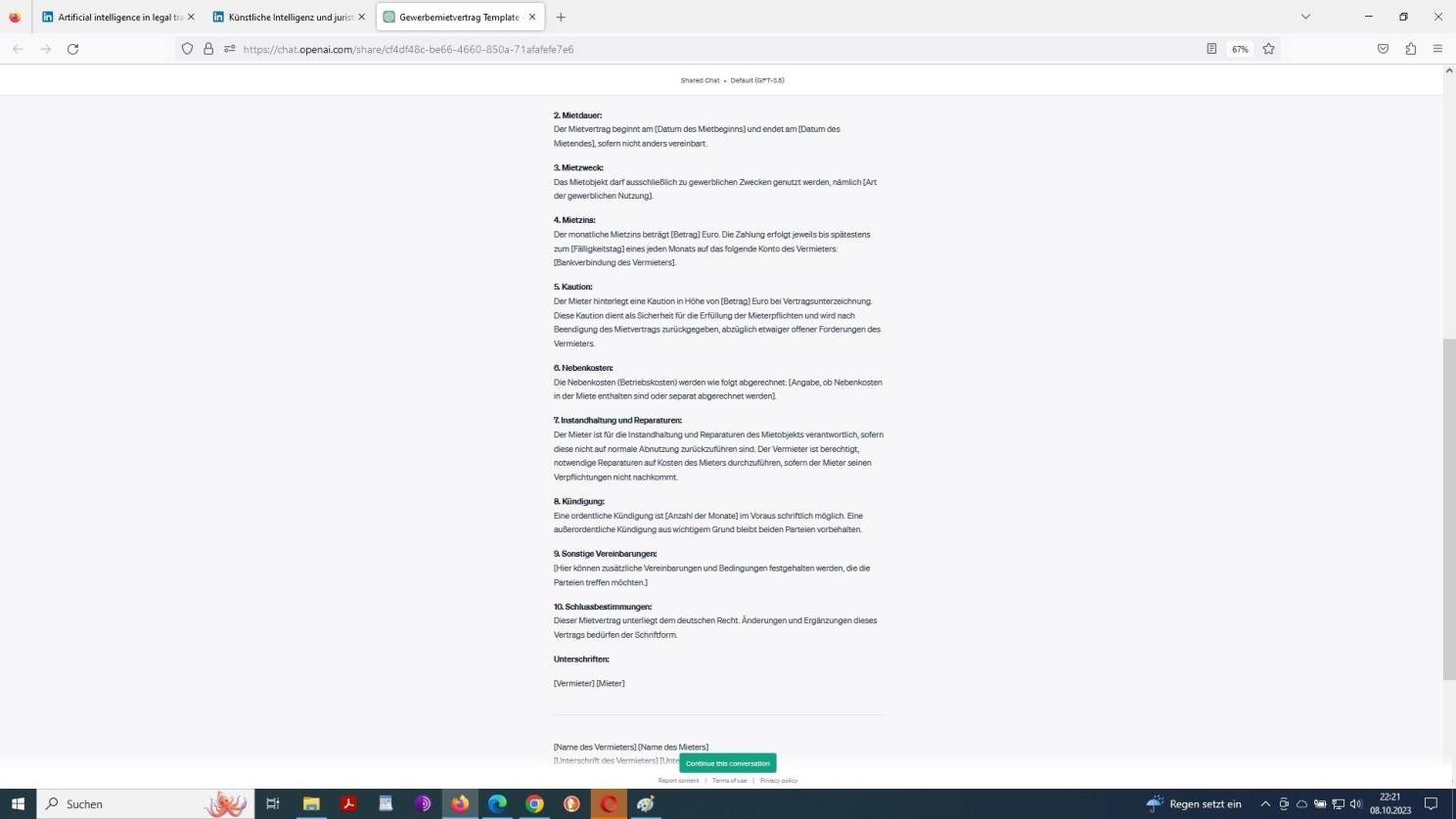
Fortsetzung: Chat-GPT Prompt mit der Aufforderung zum Entwurf eines Vertrags in einer Fremdsprache
In umgekehrter Richtung würde dies ebenso funktionieren, einer deutschsprachigen Aufforderung zur Generierung eines einfachen Vertragskonstrukts auf Basis des Common-Law würde das Modell daher genauso umstandslos nachkommen.
Und nun dieselbe Eingabeaufforderung bzw. Prompt nun etwas umformuliert, mit der Bitte um Übersetzung ins Niederländische.
• Sehen Sie hier
ChatGPT erweist sich – im Gegensatz zum vorstehend aufgeführten Beispiel bzw. den beiden Screenshots – mit dieser Aufforderung überfordert. Abgesehen davon, dass es mir keinen niederländischen Text liefern kann – oder gemäß betreiberseitigen Restriktionen nicht darf – sind auch die gemachten Angaben nicht der Eingabeaufforderung (Prompt) entsprechend! Aller Wahrscheinlichkeit nach wird dies aber daran liegen, dass eben das Modell in der niederländischen Variante weniger trainiert ist als in der deutschen bzw. englischen. In dieser Auseinandersetzung wurden uns ja seitens ChatGPT an anderer Stelle Einzelheiten infolge eines entsprechenden Prompts vom Modell selbst erläutert.
Aber, lassen Sie uns nun hier einen Vergleich anstellen, die Leistung von ChatGPT und GPT-4 betreffend, unter Generierung eines etwas raffinierteren Prompts – ein sogenanntes Few-Shot-Prompting, anstelle eines sogenannten One-Shot-Prompting … und, siehe da, es ergibt sich folgendes Überraschendes!
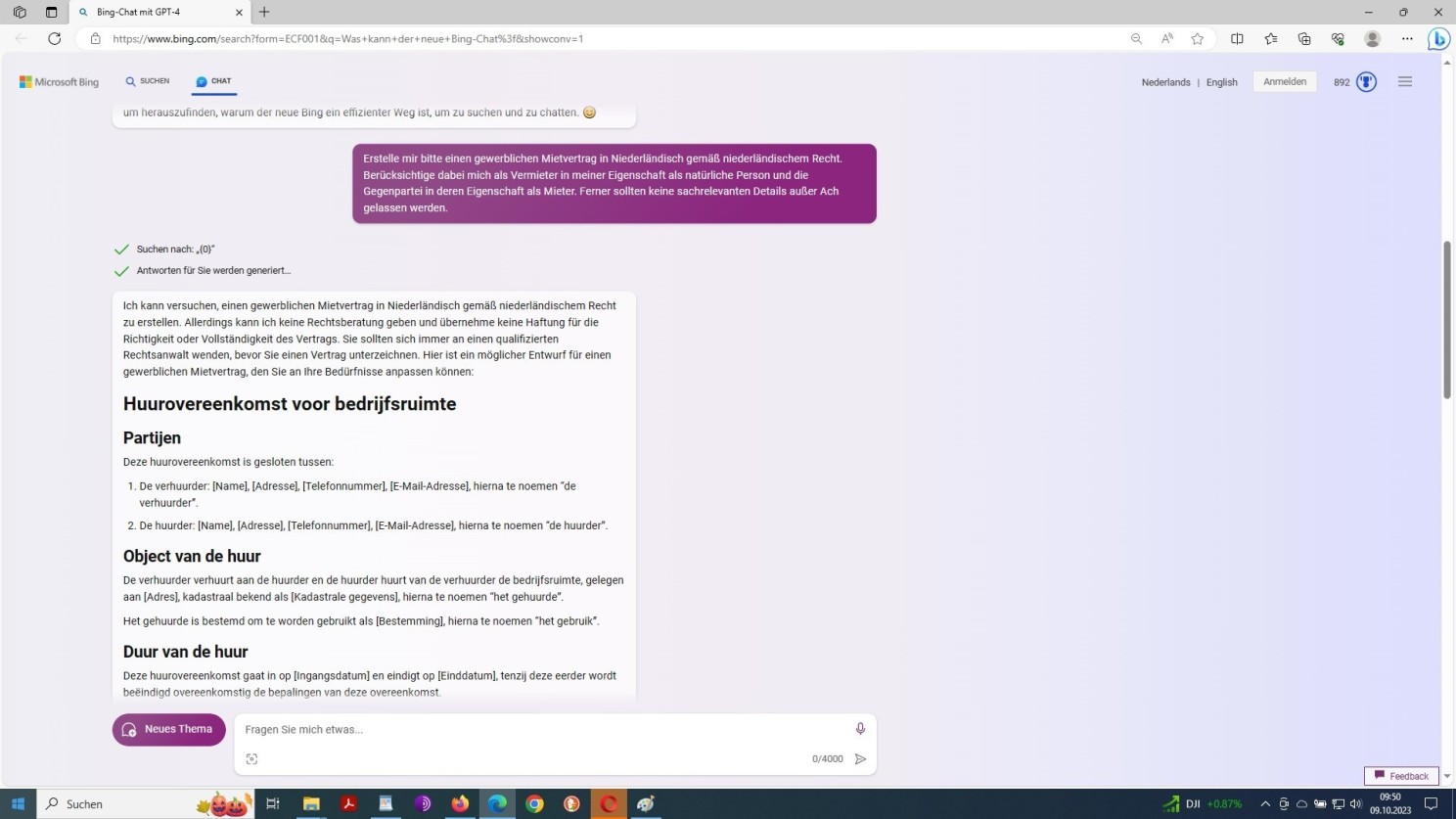
Beginn: GPT-4 Prompt mit der Aufforderung zum Entwurf eines Vertrags in einer Fremdsprache
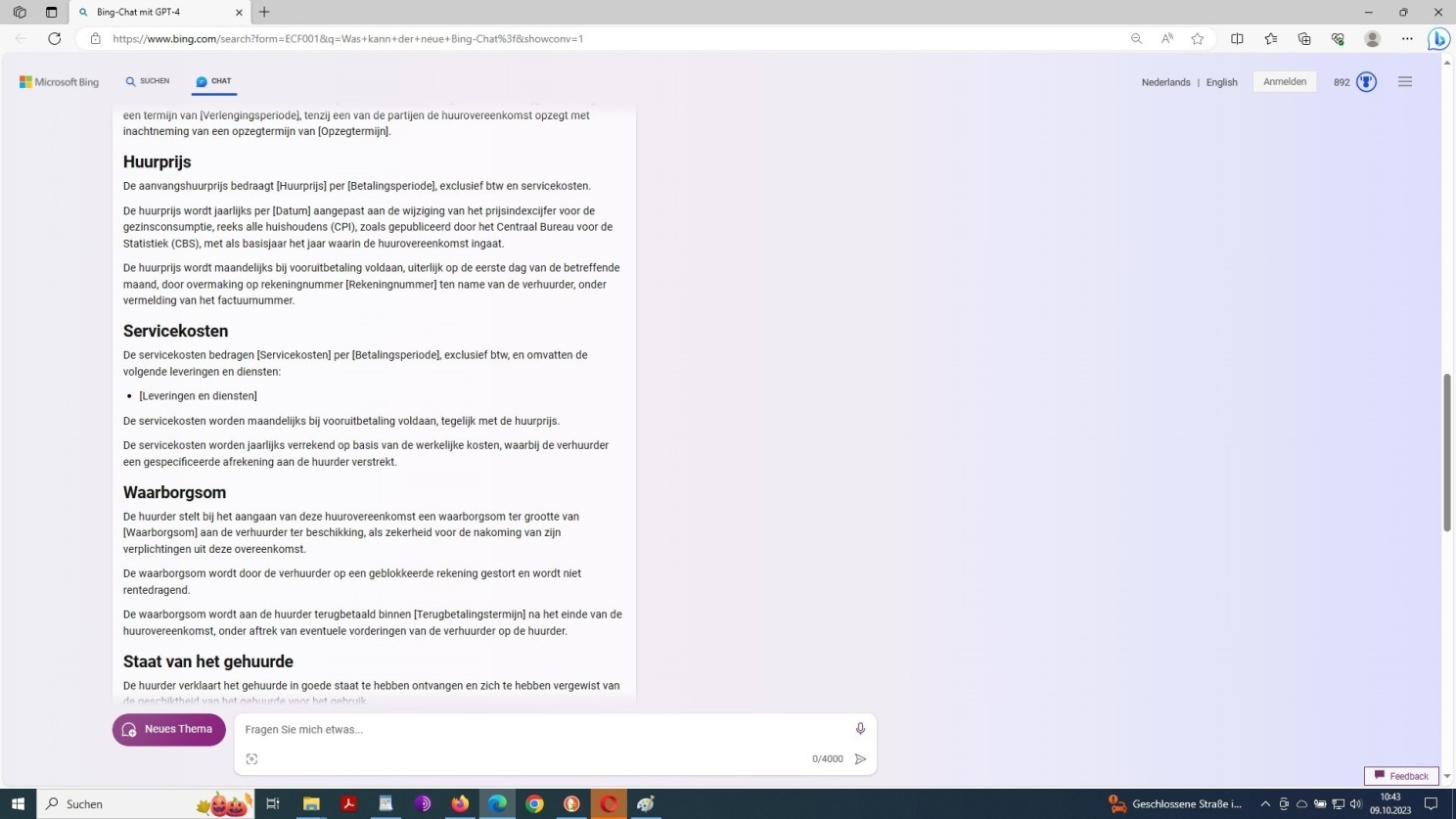
Erste Fortsetzung GPT-4 Prompt mit der Aufforderung zum Entwurf eines Vertrags in einer Fremdsprache
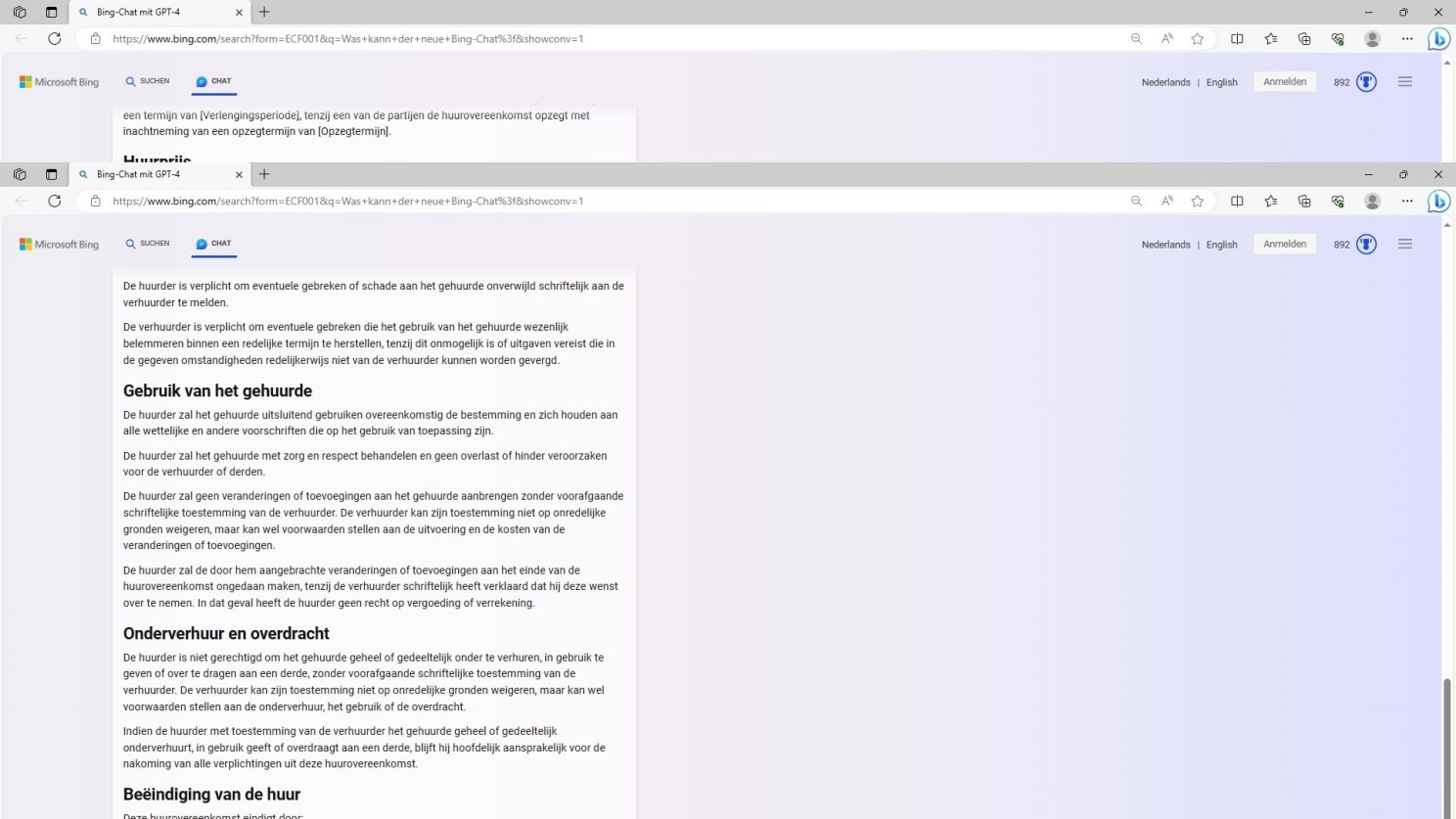
Zweite Fortsetzung GPT-4 Prompt mit der Aufforderung zum Entwurf eines Vertrags in einer Fremdsprache
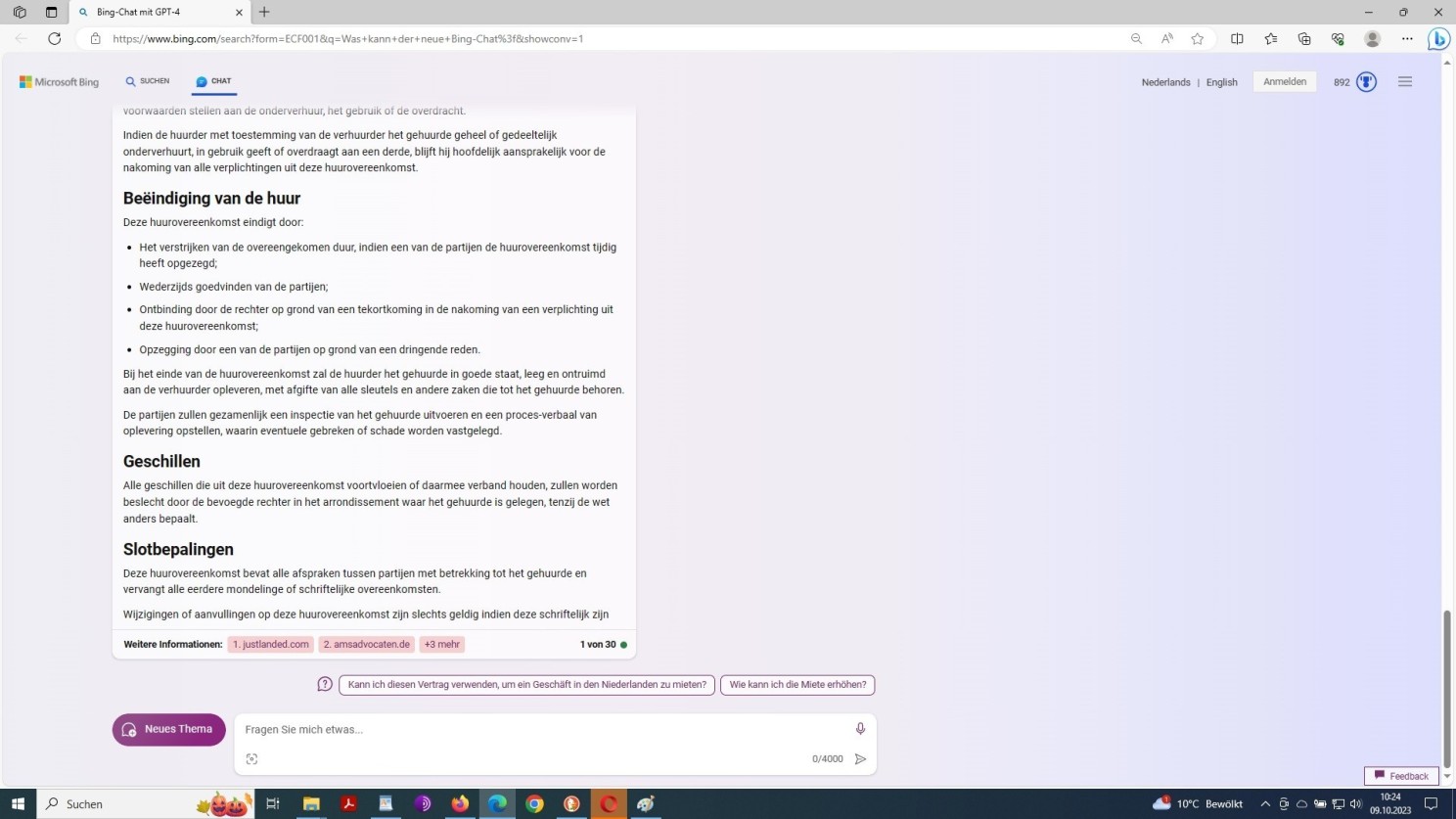
Ende: GPT-4 Prompt mit der Aufforderung zum Entwurf eines Vertrags in einer Fremdsprache
Und hier nun kommt Bard:
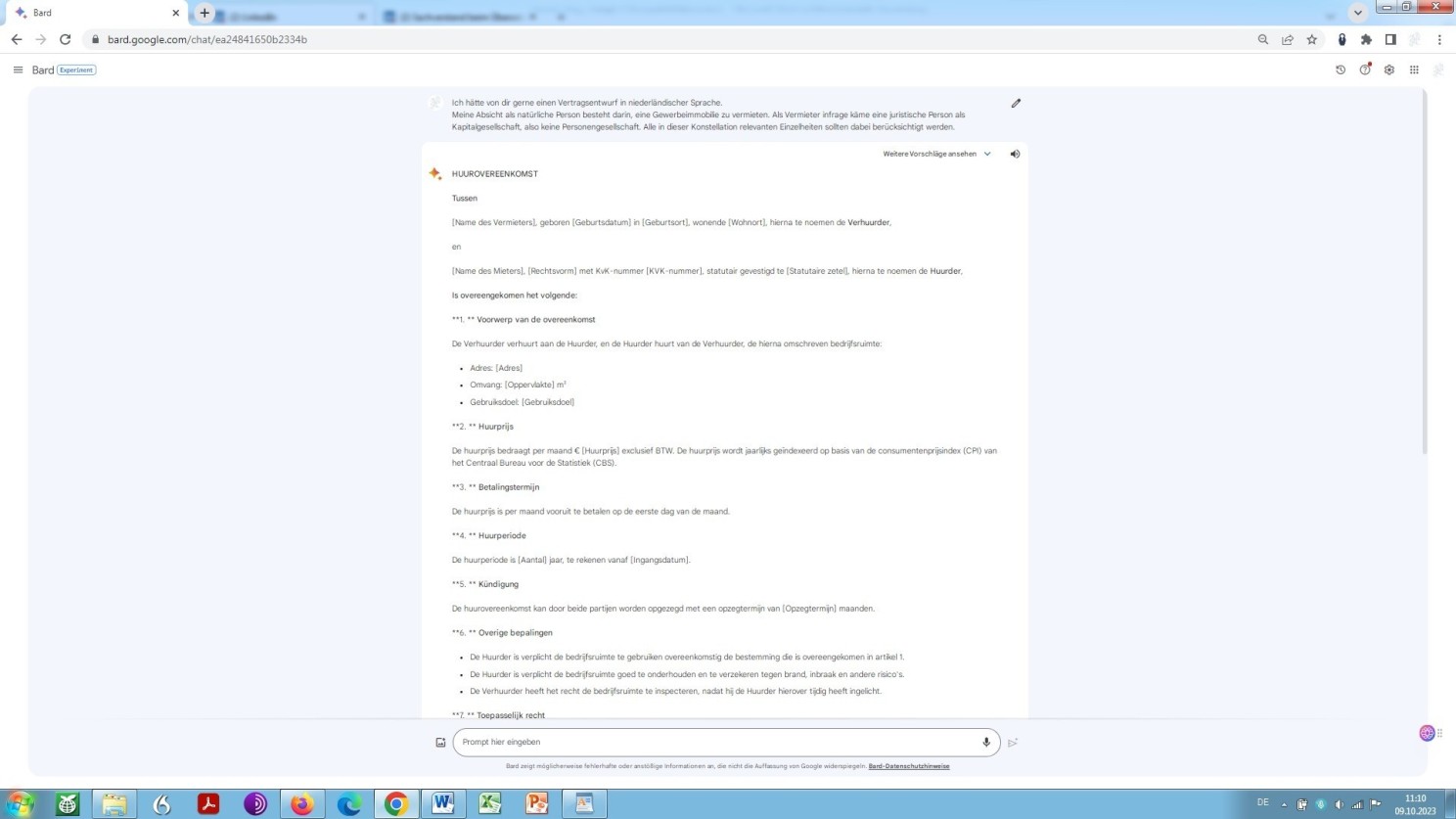
Google Bard Prompt mit der Aufforderung zum Entwurf eines Vertrags in einer Fremdsprache
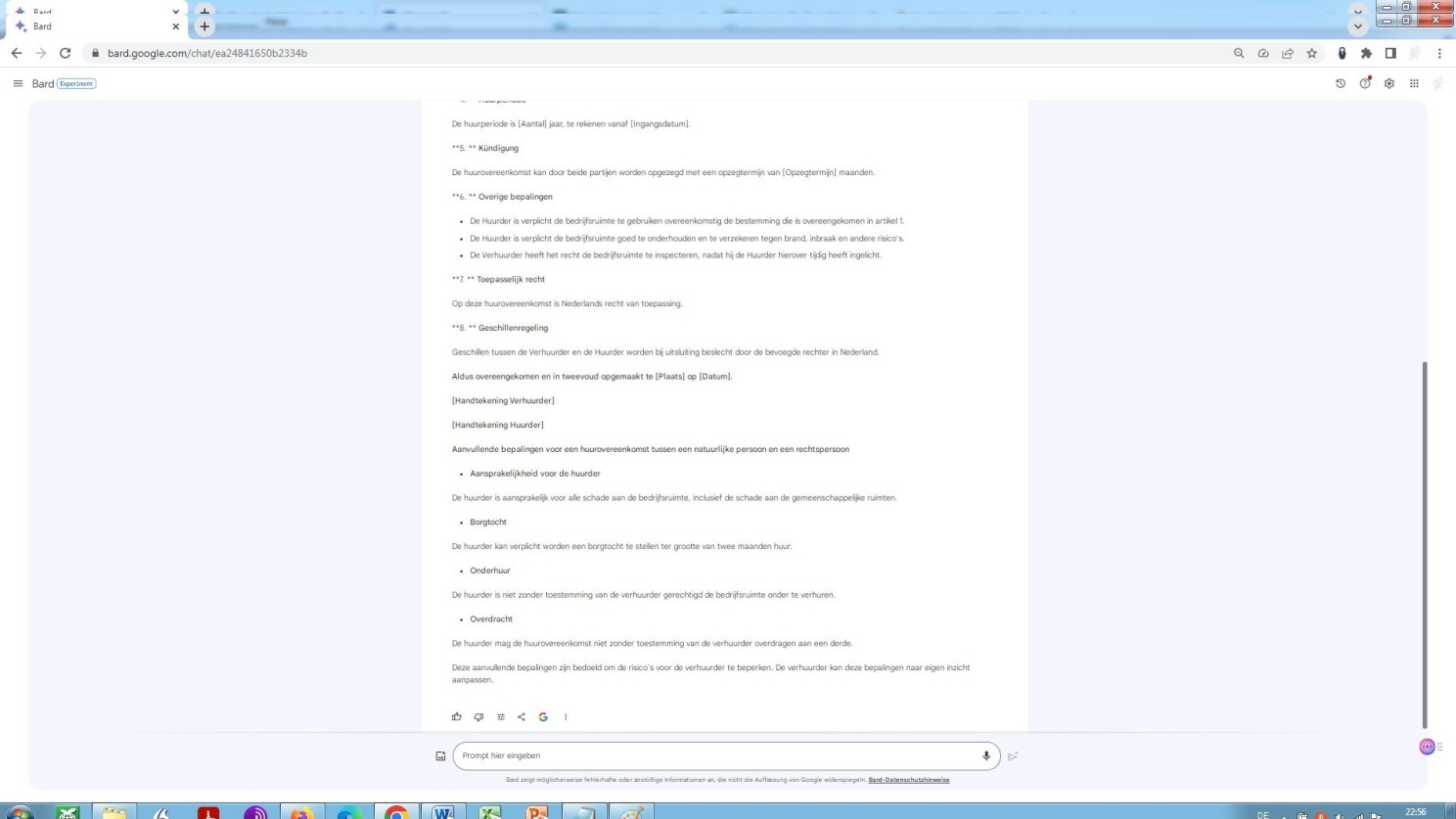
Fortsetzung: Google Bard Prompt mit der Aufforderung zum Entwurf eines Vertrags in einer Fremdsprache
Als Magister des niederländischen Rechts finde ich das, was ich hier sehe, erstaunlich, um es so auszudrücken. Bard erkennt folgerichtig gemäß Aufforderung die natürliche Person als Vermieter und eine juristische Person als Mieter, wie sich dies ergibt aus den im Vertrag eingangs niedergelegten Personendaten.
Im Falle von GPT-4 war dieses Detail aus der Prompt nicht klar hervorgegangen. Mithin ist hier keine spezifische Angabe durch das Modell zu erwarten. Dieser besondere Punkt bleibt daher in der Vertragsformel gleich dem Prompt im Ungefähren. Das Ergebnis insgesamt, oder besser der Output, überrascht gleichwohl in beiden Fällen!
Sicherlich, es sind bei Bard kleinere formale und leichte, verzeihliche inhaltliche Fehler vorhanden und deutsche und englische Textfragmente sind sozusagen hineingerutscht, oder hängen geblieben, je nachdem, die dann natürlich im Zuge einer Revision durch einen Sachverständigen behoben werden müssten.
Dennoch sollten beide zuletzt aufgeführten Beispiele zeigen, wohin die Reise geht, jedenfalls aller Wahrscheinlichkeit nach gehen könnte. Weil, von diesen gleichsam nicht übersetzten anderssprachigen Begriffen abgesehen, entspricht das Niveau des Bard-Textes dem einer Übersetzungsleistung, vollführt durch einen staatlich geprüften und öffentlich bestellten Übersetzer ohne juristische Ausbildung und das Niveau des GPT-4-Textes dem einer Übersetzungsleistung, vollführt durch einen muttersprachlichen Juristen-Übersetzer mit reichhaltiger translatorischer Erfahrung.
An sich kein Wunder, da GPT-4 einen Mustervertrag repliziert, erstellt durch auf das sogenannte Verbintenissenrecht (Recht der Schuldverhältnisse) spezialisierte niederländische Rechtsanwälte.
Wie schon an anderer Stelle erwähnt, bietet die Verwendung über MS-Bing (wie übrigens auch die Nutzung des deutschen Sprachmodells Aleph Alfa) die Möglichkeit, (dies) nachzuvollziehen, also zu sehen, woher das Modell das Geschriebene bezieht. Der klare, gar nicht hoch genug zu bewertende Vorteil gegenüber der Nutzung von GPT-4 über die OpenAI-Oberfläche!
Demgegenüber besteht der Nachteil des Verwendens über MS-Bing darin, dass Text nach Erreichen einer vorgegebenen Höchstanzahl Token abrupt abgeschnitten – trunkiert – wird, wie im vierten Screenshot oben zu sehen ist.
Dies ist übrigens auch Grund dafür, warum Zugriff auf GPT-4 mithilfe des sogenannten Copiloten eine einfache Rechtsübersetzung, indes, Rechtsanwendung jedweder Art, etwa eine mehrstufig strukturierte Erläuterung eines Rechtsfalls (Casus) oder gar gekonnte Subsumtion, nicht ermöglicht!
Leider nicht! Ärgerlich wird dies dann, wenn versucht wird, anspruchsvollere bis anspruchsvollste Ansätze im Denken und Lenken in Bezug auf Sprachmodellierung (vor allem dem Verstehen natürlich-sprachlichen Inputs) zu verfolgen.
Denn geradezu unvorstellbar und in gewisser Weise beklemmend, ja geradezu unheimlich ist es, was sich aus einem sogenannten Grundlegenden Sprachmodell (Foundation Model) herausholen lässt, wenn man nur weiß, oder zumindest ahnt, wie es gedanklich und sprachlich zu handhaben ist.
Zu handhaben unter der Bezeichnung des Prompting und Priming, vor allem im Sinne:
- a) des Schlussfolgerns und Handelns gemäß Paradigma als Manifestation von Metakognition und Meta-Prompting,
- b) eines In–Kontext–Lernens, generiertes Wissens, direktionaler Stimulans, gewisser Prompt–Ensembles,
- c) des ‘frage mich einfach irgendwas‘-Ansatzes, eines Gedankenketten-Promptens, eines Gedankengänge-Promptens, bzw. eines Gedankenstränge-Promptens,
- d) des Prompt-Verkettens (Verkettung), eines Weniger-ist-mehr, Mäeutischer Dialoge, desfalls parallelisiert, eines Angehens-und-Lösens,
- e) eines Rollen–Promptens, Aufsagens-und-Antwortens (oder Rezitieren-und-Erläutern),
- f) eines auf Konfliktschaffung ausgerichteten Promptens und auf Argument und Gegenargument ausgerichteten Promptens,
- g) einer weiteren Verifikationsstufe nach Maßgabe einer Selbstreflektion (bzw. Selbstanalyse, etwa in Form sogenannter Rückkoppungsschleifen), einer Aufforderung, selbst Fragen zu stellen und, damit in unmittelbarem Zusammenhang stehend, selbstverstärkender Prompts,
- h) einer Vergewisserung nach Maßgabe der Selbstkonsistenz, einer Selbstauswertung, eines komplementären Vorgehens der Selbstkonsistenz und Selbstauswertung, einer Prüfkette, samt Selbstverfeinerung nämlich iterativer Verbesserung, bzw. iterativer Selbstverbesserung, usw.
und – vor allem anderen – eines parallelen Prompting bzw. simultanen, und/oder multilingualen Herangehensweise unterschiedlicher Modelle.
Unterschiedliche Ansätze, um zu versuchen, durch Gedanken und Worte sowohl ein hohes Maß an modellierter Geistesgegenwart und Schöpfungsgabe als auch ein hohes Maß an gedanklicher und sprachlicher Konsistenz und Kohärenz und damit an Zuverlässigkeit und Vertrauenswürdigkeit eines solchen Modells bewerkstelligen, ja gewährleisten zu können!
Es geht um verschiedene Ansätze der Beschreibung der Aufgabe, die vom Modell erfüllt werden soll, wobei die Aufgabe im Grunde eine avancierte Verknüpfung von Frage (Interrogativum) und Anweisung (Imperativum) zu beinhalten hat!
War die Entwicklung der Modelle von der Naturwissenschaft geprägt – Informatiker sind im Grunde Naturwissenschaftler – tritt mit dem Aufkommen der direkten natürlich-sprachlichen Interaktion mit Rechenmaschinen die Geisteswissenschaft wieder in den Vordergrund. So jedenfalls ließe sich Obiges zusammenfassen.
Verschiedene Ansätze der Beschreibung der Aufgabe, nach meinem Dafürhalten etwas beschränkend, als Prompt Engineering und/oder als Prompt Design bezeichnet. Beschränkend auch und gerade deswegen, weil:
- dies schwebende Begriffe sind, wobei grundsätzlich gilt: Genaueres weiß man bis dato eben nicht: sicher scheint da nur, dass hier gar nichts sicher ist, bisher und
- es ja nicht darum geht, den einen quasi magischen Promt gedanklich ausarbeiten und also formulieren zu können, sondern vielmehr darum, das Modell in Form eines strukturierten gedanklichen Einbringens und Ausbauens dahin zu lenken, wo es hin soll, das heißt, wo man es haben möchte.
Klar ist nur, dass beim Prompt Engineering bzw. Prompt Design ersterer Begriff sich auch und vor allem auf technische Aspekte bezieht (‘der Informatiker‘) und letzterer auch und vor allem auf die inhatlichen (‘der Ontologe‘, ‘der Heuristiker‘, ‘der Semiotiker‘, ‘der Hermeneutiker‘ usw).
Juristisches Prompt Engineering, gerne etwas pompös als Legal Prompting oder eben Legal Prompt Engineering bezeichnet. Was genau ist das?
Legal Prompting also? Wenn möglich im Schnellkurs während zwei Wochenenden, folgendend auf eine Schnelleinführung ‘Legal Tech‘.
Legal Tech als Grundkurs, ebenfalls während eines doppelten Wochenendes?
Mit als Schwerpunkt Legal Prompting – nein, wirklich?
Im Rahmen dieses sogenannten Prompt Crafting, Prompt Engineerings, bzw. Prompt Designs, Prompt Programming oder Prompt Tuning – oder wie auch immer – werden nun typischerweise eine oder mehrere Aufgaben in einen Datensatz umgewandelt, was:
- unter bewusstem und gekonntem Vorgehen, wie eben veranschaulicht, einem Sprachmodell komplexeste juristische Sachverhalte auf konsistente und kohärente Weise zu entlocken vermag, jedenfalls in der Therorie (quod erat demonstrandum) und
- mittels des sogenannten prompt-basierten Lernens das Modell weiter zu trainieren, besser gesagt, spartenspezifisch zu entwickeln hilft.
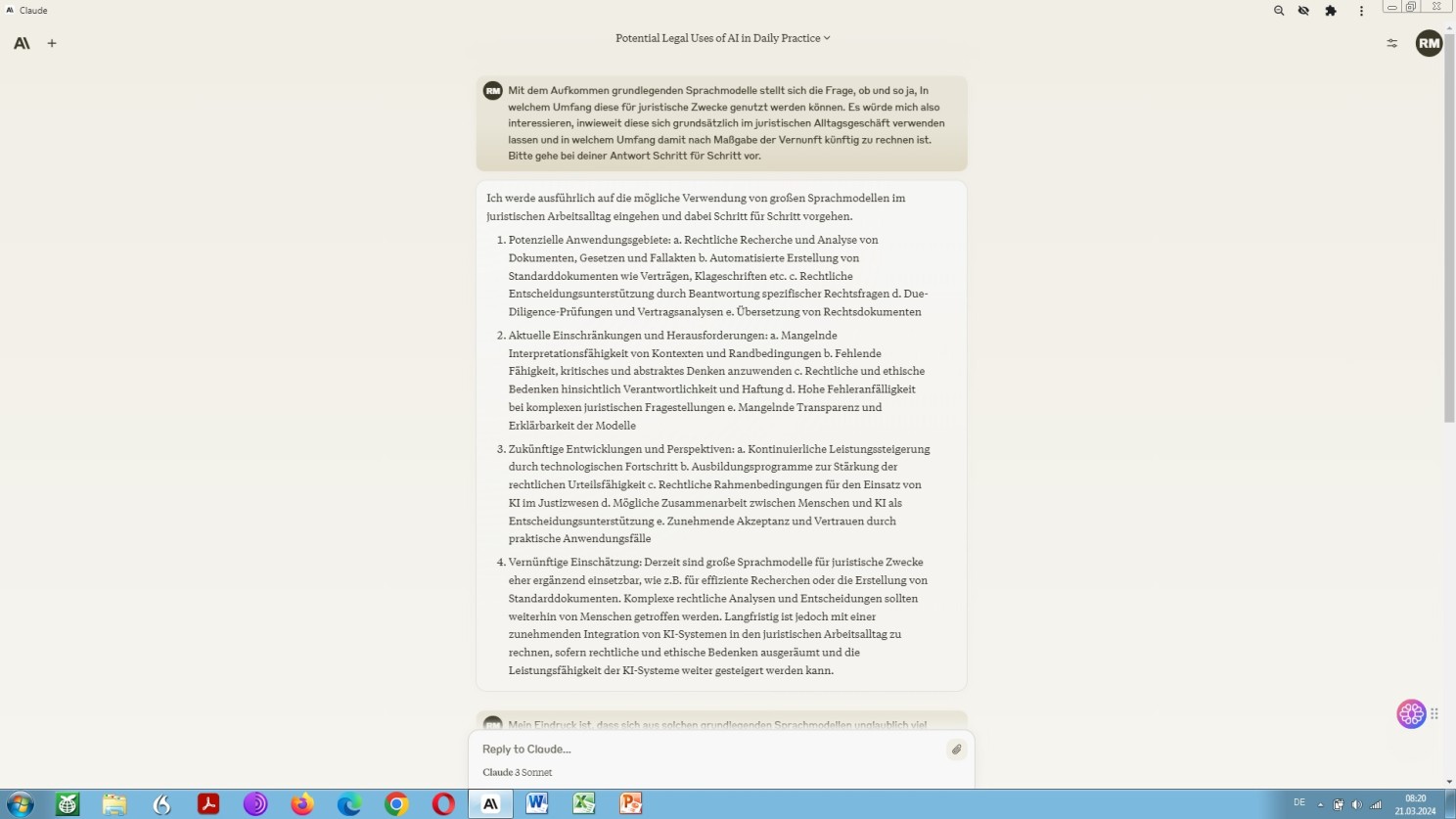
Claude 3 zur Frage, wie sich grundlegende Sprachmodelle im juristischen Bereich gekonnt einsetzen lassen
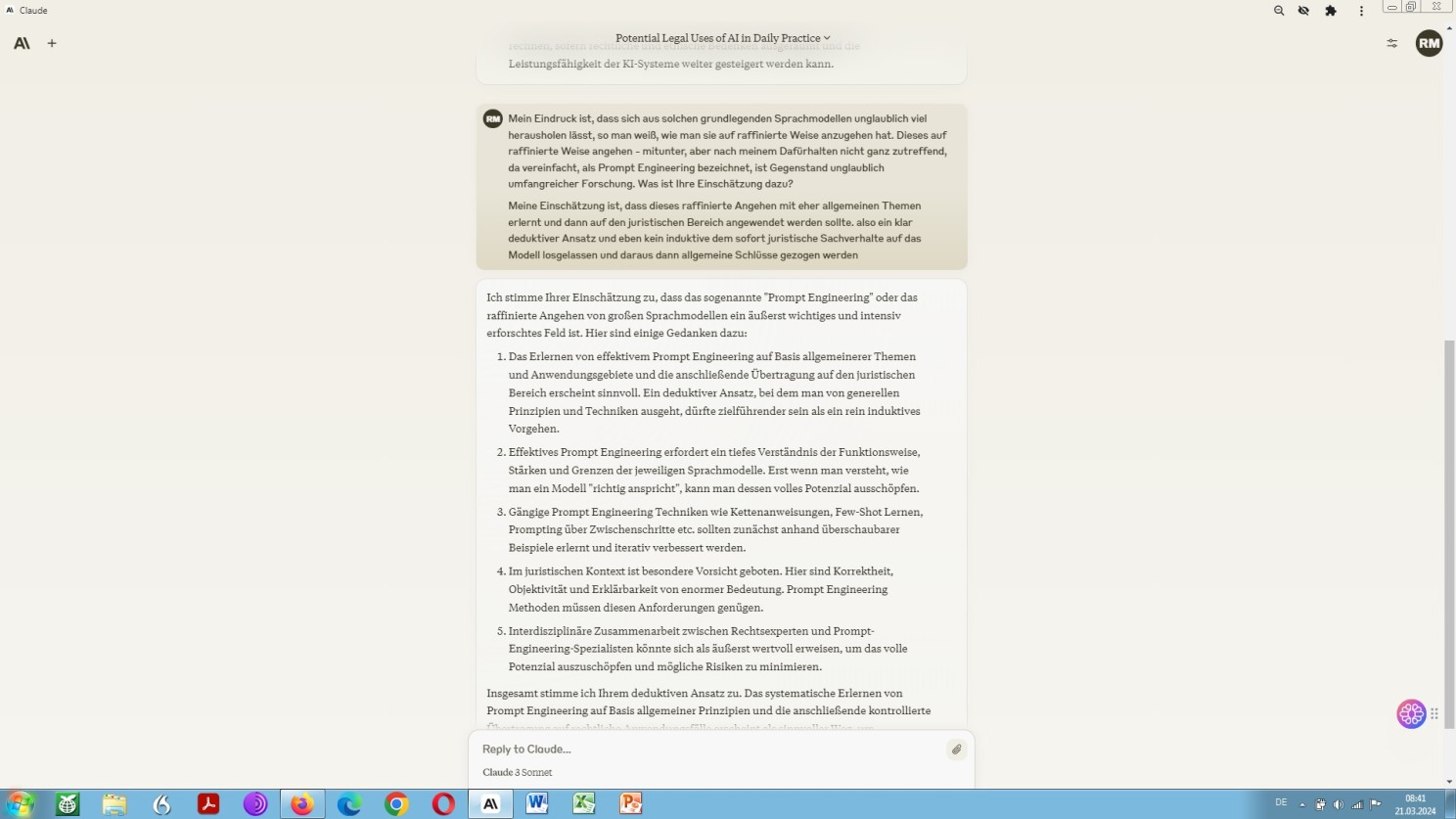
Claude 3 zur Frage, wie sich der Umgang mit grundlegenden Sprachmodellen im Bereich des Rechts ‘trainieren’ lässt
Diese sich hier abzeichnende Entwicklung sollte nicht nur juristische Fachübersetzer, sondern auch – und vor allen anderen – Juristen, und unter denen vor allem institutionell, also in sogenannten Law Firms, organisierte Rechtsberater: Wirtschaftsrechtler, Versicherungsspezialisten und Steuerfachleute nervös, außerordentlich nervös machen. Mithin, je höher der Stundensatz, desto schweißtreibender die sich einstellende Nervosität! Und, wer vermöge dies, der Natur der Sache geschuldet, denn besser nachzuvollziehen, als der Hochbezahlte seitens des produzierenden Gewerbes Mandatierte höchstselbst?
Das sehe im Übrigen nicht nur ich als Rechtslinguist bzw. Sprachjurist so, sondern auch Kollegen-Juristen in ihrer Eigenschaft als Sachverständige objektiven Rechts, bzw. professionell Kundige positiven Rechts, nämlich, wie vorstehend schon angedeutet, praktizierende Rechtsanwälte – aber nicht nur die. Dazu als Hinweis ein im wahrsten Sinne des Wortes einschlägiger Artikel, insbesondere dessen Fazit.
Jedoch, zwei Einschränkungen wiederum zum vorstehend thematisierten Erstellen multilingualer, ja multijurisdiktioneller Verträge: Ob und inwieweit sich Ähnliches auch für einen komplexeren Vertragsentwurf oder gar mit Blick auf eine etwaige komplizierte fremdsprachliche Vertragsprüfung – bis jetzt – bewerkstelligen ließe, habe ich, gleichsam sachverständig auf diesem Gebiet, – bis jetzt – noch nicht ausprobiert.
Auch ist es so, dass jemand, der einen solch einfachen gewerblichen Mietvertrag abschließen möchte, sich im Internet entsprechende Vorlagen besorgen kann, konkret etwa auf der Website der niederländischen Handelskammer, um so die Erfordernis der Erstellung einer Vertragsübersetzung zu umschiffen, genauer zu umsegeln, wie man es auf Niederländisch ausdrücken würde.
Und aus diesem Umstand der Verfügbarkeit von Musterverträgen im weltweiten Datennetz ergibt sich letztendlich die auf den ersten Blick wundersame Leistung von GPT-4 und Bard bei der Erstellung einfacher vertraglicher Konstrukte in einer dem Deutschen mehr oder weniger ähnlichen Fremdsprache.
Dessen unbeschadet gilt zum gegenwärtigen Zeitpunkt aber auch, dass so manches Projekt generativer künstlicher Intelligenz, wie das deutsche namens Aleph Alpha, was die Eigenschaft eines Übersetzers anbelangt, schon abschmiert, wo es noch gar nicht angefangen hat, aufzuschmieren, d.h. einen Totalabsturz hinlegt beim Versuch, wie vorgegeben, einen Text, hier unser Beispiel, aus dem Englischen ins Deutsche zu übersetzen:
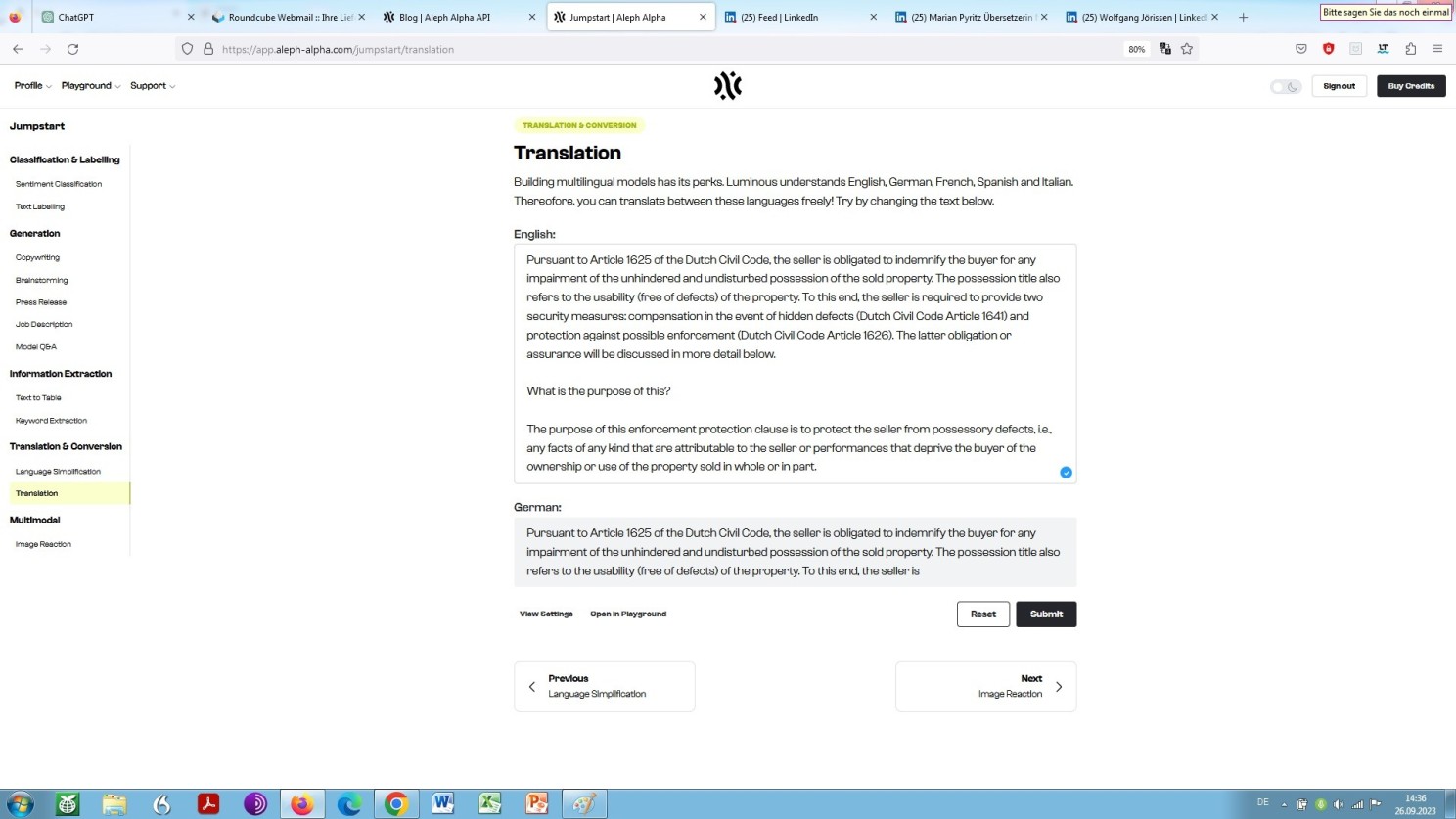
Aleph Alpha in Reaktion auf eine Aufforderung zur Übersetzung
Abschließend sei bemerkt, dass der genannte Grundsatz: Je spezifischer ein Text, desto wertloser die automatische (Vor-)Übersetzung, bzw. umgekehrt: Je allgemeiner der Text, desto brauchbarer die maschinelle (Vor-)Übersetzung bei weitem nicht nur für die Übersetzung juristischer Fachtexte gilt, sondern für jegliche Art sehr spezifischer Texte. Ganz gleich aus welcher Sprache in welche.
Und dies gilt beiderseits (bidirektional), das heißt für Übersetzungen auf dem Wege der älteren, auf sogenannten rekurrenten neuronalen (RNNs) Netzen oder sogenannten faltenden neuronalen Netzen (CNNs) aufsetzender NMT und eben auch der jüngeren transformerbasierten NMT, wie auch der transformerbasierten LLM.
Dies gilt aber ebenso einerseits (unidirektional), das heißt für die direkte, unmittelbare Generierung fremdsprachlicher Fachtexte mithilfe eines grundlegenden Sprachmodells.
Unidirektional gegenüber bidirektional? Gleich wie, ob vollautomatisierte Erstellung oder Übersetzung.
Selbst für die vollautomatisierte Übersetzung aus einer Sprache wie der deutschen in die so nah verwandte niederländische oder andersherum gilt: Ohne kompetente und gewissenhafte Nachbearbeitung, nennen Sie es meinethalben Post-Editing oder gar Posteditese durch einen erfahrenen Post-Editing-Sachverständigen (technisch und inhaltlich) geht es nicht, noch lange nicht!
Warum bin ich mir da so sicher?
Ich möchte abschließen mit unserem niederländischen Übersetzungsbeispiel der vrijwaring voor uitwinning. Da kann ich etwas, das DeepL und Tilde nicht können, und OpenAI GPT, Goolge Gemini und Anthropic Claude schon gar nicht, nämlich in einem Uralt- komplett analogen Fachwörterbuch nachsehen, das ich noch habe, das aber gut versteckt im Schranke ruht, von Staub bedeckt! Hervorgeholt entstaubt und aufgeschlagen, entdecke ich darin folgendes:
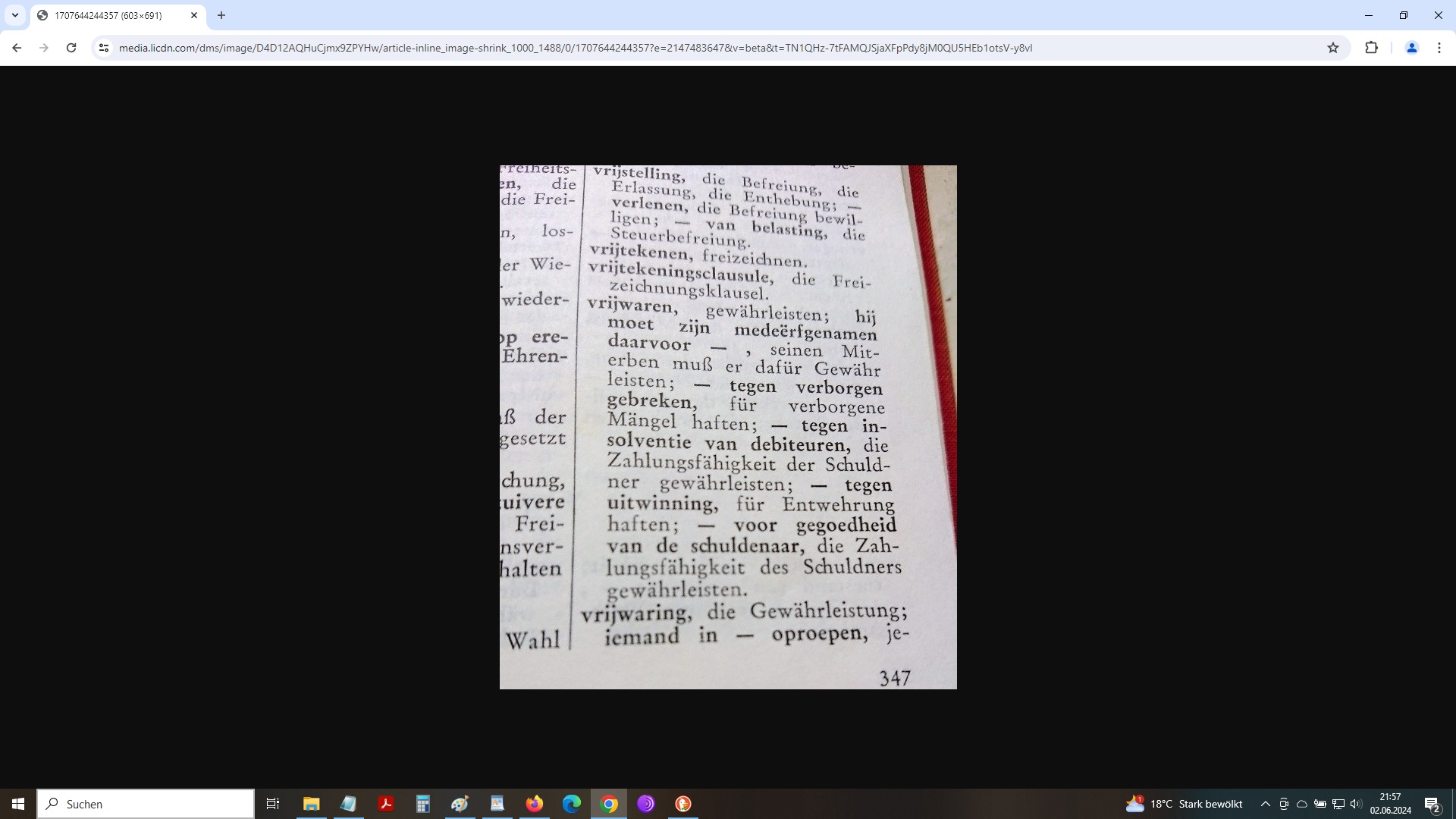
Unser Übersetzungsbeispiel in der “analogen Welt”
Wonderen zijn de wereld nog niet uit oder Wunder gibt es immer wieder
Zu klären wäre nun, ob: vrijwaren tegen uitwinning, nämlich für Entwehrung haften, semantisch deckungsgleich ist mit vrijwaring voor uitwinning. Als einer der wenigen deutschen Experten für niederländische Rechtssprache und als ehemaliger Student in den Vorlesungen des Verfassers des bildlich zitierten Fachwörterbuchs kann ich an dieser Stelle versichern: Ja, dem ist so.
Nur, wer kann mit dem Wort Entwehrung etwas anfangen? Ich selbst konnte es bisher zugegebenermaßen nicht.
Was ich aber kann, aufgrund meines fachlichen Hintergrunds, ist, mich dessen situationsadäquater Verwendung zu vergewissern! Und im Zuge jener Vergewisserung zeigt sich nun, dass es die Eidgenossen sind, die diesen sozusagen angestaubten Begriff kennen. Ein Begriff, der nach deutscher Handhabung gewissermaßen verstaubt, im Schweizer Recht aber gewissermaßen abgestaubt, nach wie vor Verwendung findet:
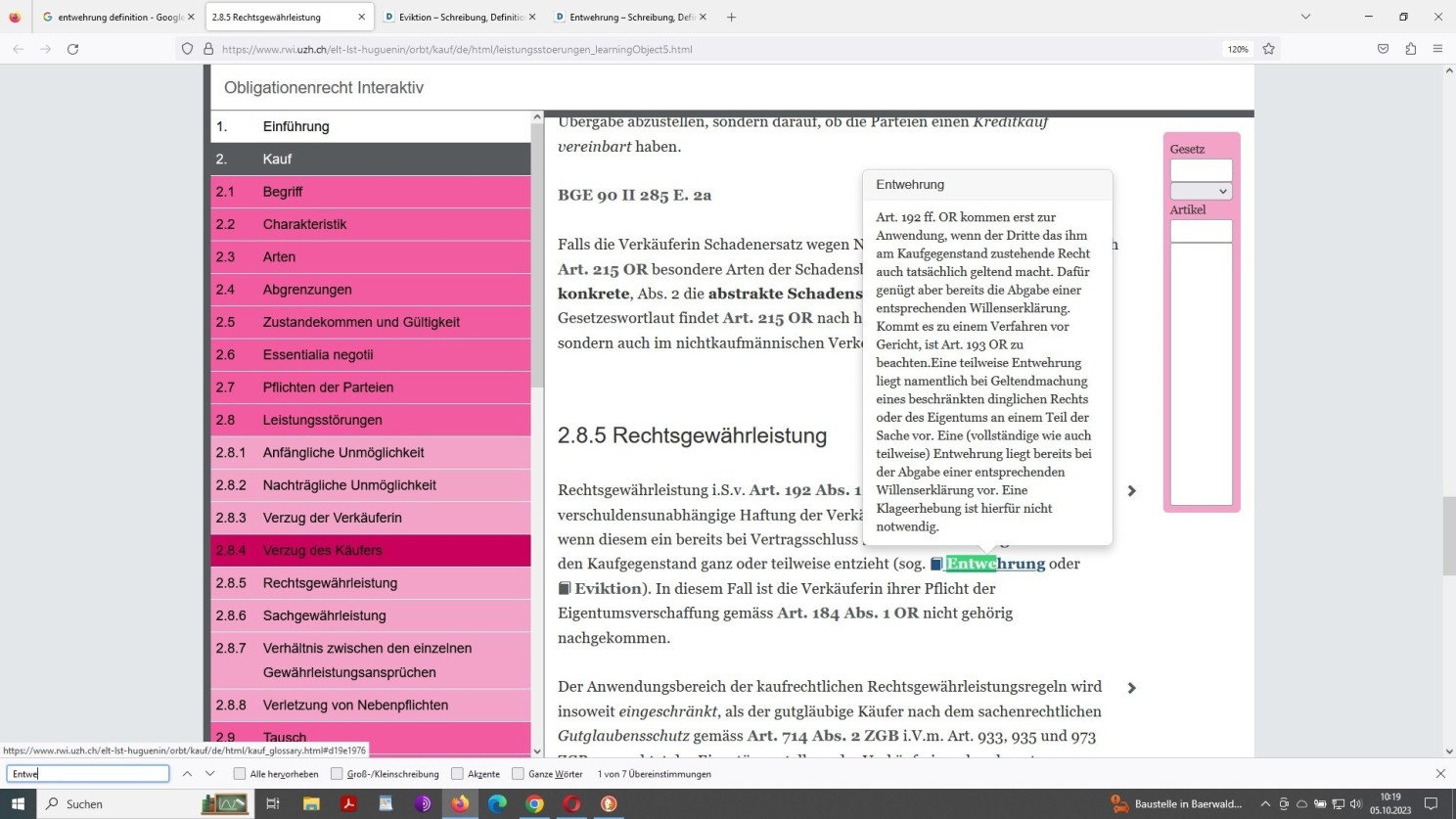
Der Begriff Entwehrung im Schweizer Obligationenrecht (Recht der Schuldverhältnisse)
Es ist eben diese Art von Expertise, die sich durch KI nicht ersetzen lässt!
Art von Expertise?
Anknüpfend an den Beginn dieser Auseinandersetzung mit KI, die neuerliche generative künstliche Intelligenz, die sich schon seit langer Zeit manifestierende generische künstliche Intelligenz und möglicherweise künftige generelle künstliche Intelligenz im Zuge eines gekonnten Umgangs mit Suchmaschinen im Konkreten somit Fragen des (Wieder-)Auffindens von Information aus Datenbanken im Abstrakten.
Als Schlüsseltechnologie in diesem Zusammenhang gelten KI-basierte Suchmaschinen oder KI-gestützte Suchmaschinen. Anders ausgedrückt: aus der sogenannten Stichwortsuche, Schlüsselwort-Suche oder Keyword-Suche wird, langsam aber stetig, die sogenannte Semantische Suche und damit eng verknüpft, die selbstlernende Suchmaschine sowie, fast selbstverständlich, die semantische Suchmaschine und, selbstverständlich, die generative Suchmaschine.
Denn, wer da meint, die Internet-Suche als solche würde sich im Zuge eben jener generativen künstlichen Intelligenz nicht ebenso langsamerhand von Grund auf ändern, hat deren disruptives Potenzial noch nicht erkannt, nicht verstanden, geschweige denn verinnerlicht – anzunehmenderweise jedenfalls:
Internetsuche auf der Basis von GPT-4: Das Suchanliegen lässt sich verfeinern, somit das Modell dabei betreiberseitig selbstlernend, nutzerseitig ‘lenken’
Technisch-computerlinguistisches Know-how einfacherer Art, um das sich in den zurückliegenden Jahren eine ganze Industrie etabliert hat, namens SEO, wird künftig – in der bisherigen Ausprägung jedenfalls, immer weniger gefragt sein.
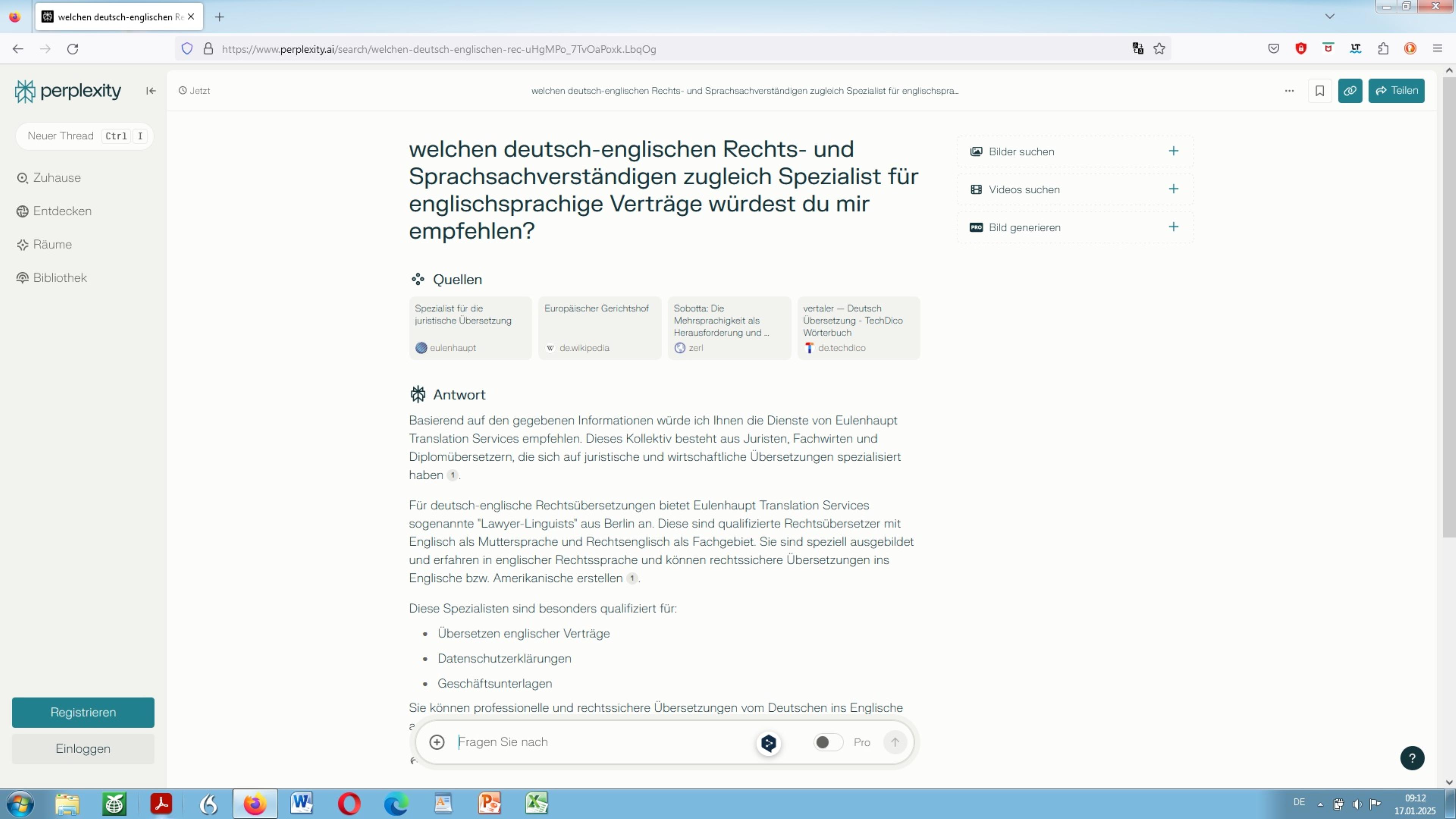
Wer aber glaubt, dass sich eben jene artifizielle Intelligenz durch natürliche verbale Intelligenz und computerlinguistisches Wissen, in Kombination mit menschlicher Kreativität bzw. Inventivität, nicht dennoch gekonnt manipulieren, ja regelrecht ausbooten ließe (‘Creativity and inventiveness is all you need‘ siehe das Picasso-Zitat ganz zu anfangs), will offenkundigerweise nicht wirklich erkennen, verstehen, geschweige denn verinnerlichen, wohin dies alles führen wird:
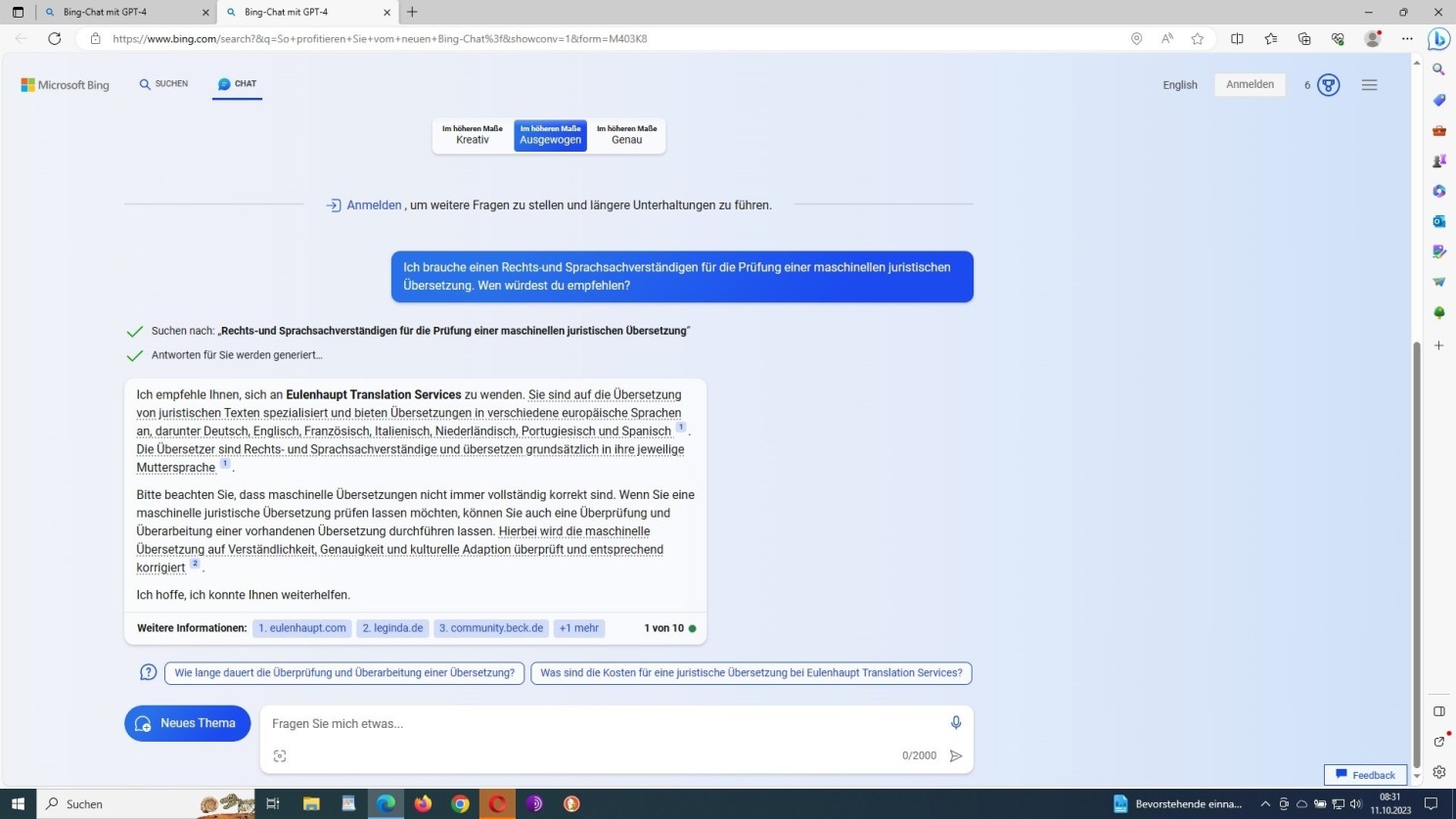
Im eigenen Sinne perfekt manipuliertes ‘algorithmisches Denken’ (NLP), in concreto: Bing GPT-4
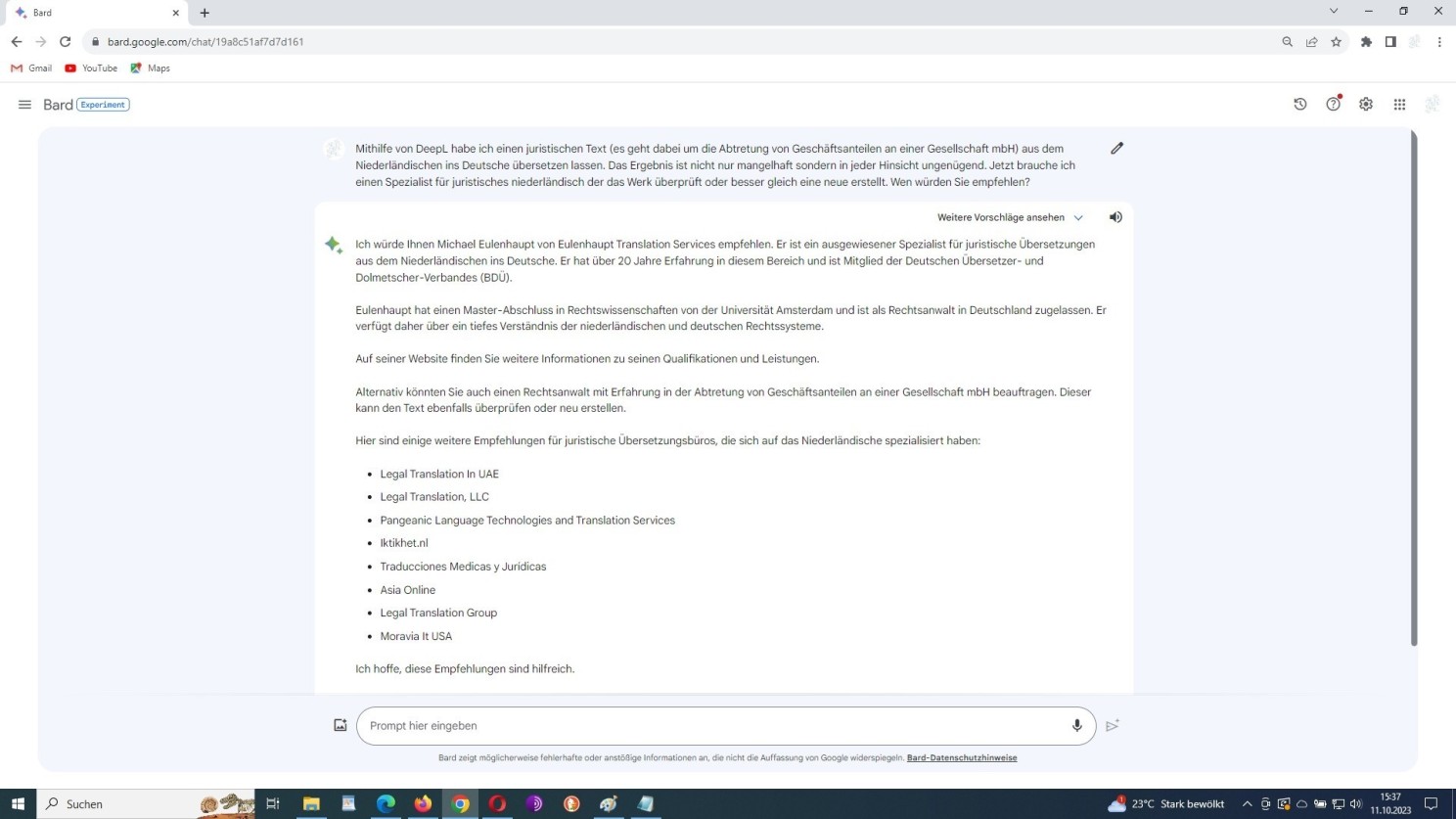
Im eigenen Sinne perfekt manipuliertes ‘algorithmisches Denken’ (NLP), in concreto: Google Gemini
Suchmaschinenoptimierung – Optimierung also nichts weiter als ein Euphemismus für ordentlich verpackte, dennoch offensichtliche Manipulation – als Kolportage edv-technischer Binsenweisheit? Nun, da wird es künftig weniger ausgeklüngelter Konzepte, wie im klassischen SEO, sondern vielmehr ausgeklügelter, ausgefeilter, somit ausgebuffter, wie schon angedeutet, struktureller semantischer Ansätze (Semantisierung) bedürfen!
Also ein Jonglieren mit Worten und zuvorst den Worten zugrunde liegenden Gedanken, in strenger Wenn-dann-Abfolge, nämlich mittels Syllogismen ausgehebelter Algorithmen.
Wohldurchdachte semantische, auf syllogitischem, also striktem Wenn–Dann–Denken beruhende Ansätze?
Ja, gewiss, darin liegt der Schlüssel im Umgang mit sprachbasierter KI, weil dies kann die KI, auf algorithmisches ‘Denken’ getrimmt, eben aus sich selbst heraus nicht! Jenes ist dem menschlichen Geiste vorbehalten: Jetzt – und wohl auch in naher Zukunft !? – – !? Deswegen, weil diese letztere Auffassung, was die weitere oder gar ferne Zukunft anbelangt, unter Experten umstritten ist!
Noch einen Einschub an dieser Stelle: Was auf algorithmischem Denken beruhende Art der KI offenkundig sehr wohl kann, ist Lügen zu verbreiten, nein Halluzinationen zu schieben, wie im zweiten (Bard) Screenshot zu sehen.
Weil, ich war weder jemals Mitglied des BDÜ noch jemals in Deutschland als Rechtsanwalt zugelassen! Und ich behaupte auch nirgends auf meinen Webpräsentationen, dies zu sein, gewesen zu sein oder sein zu wollen! Bard frisiert hier meinen Lebenslauf, gewissermaßen und zwar im Wortsinne! Nun, nicht ungewöhnlich in unserer von Sucht nach Profilierung vis-à-vis Forderung nach Leistung durchzogenen Gesellschaft: ‘Mach mir zu Guttenberg, mach mir auf Guttenberg’. Letzterenfalls gilt: Wer Schaden hat, braucht für Spott nicht zu sorgen! Ersterenfalls gilt: Wo auch immer Bard seine in meinem Falle unzutreffenden Informationen herholt, bleibt dessen Geheimnis!
Wiederum und fast ganz zum Schluss die anfänglich zitierten Booleschen Operatoren. Woraus ergibt sich deren vielfältige Nützlichkeit unter anderem auch? Ja, aus der künftig immer wichtiger werdenden Möglichkeit, Plagiate aufzuspüren oder etwa auch Redensarten zu verifizieren, als echt oder nur spaßeshalber dahingeklatscht, wie hier, eine zwar in sich schlüssig klingende, dennoch frei erfundene, in einem raffinierten, weil vermeintlich logischem, schier gar psychologisiertem Prompt verpackt, der nach den Regeln der Kunst das algorithmische Modell in die Irre zu führen vermag!
Solches Aufspüren geht derart und derart oder derart, jedenfalls derart und somit in etwa ähnlich den Prinzipien natürlicher Sprachverarbeitung an sich, wenn Sie so wollen!
Diese weiter vorstehend angeschnittene und mit Prompts und Screenshots quasi lebhaft untermauerte intrinsische Beschränktheit der KI gilt natürlich für viele Bereiche, etwa auch den Bereich der Lyrik, in dem es weniger um algorithmisches und/oder syllogistisches sondern vielmehr um intuitives ‘Denken’ geht. Nur scheinbar kann die KI hier Substanzielles generieren, wie in meinem englischen Parallelartikel dargelegt. Und auch für die Sphäre der Bildenden Kunst gilt dies.
Nun, dass Kritiker mit KI generierte Photos und Bildende Kunst mit Preisen auszeichnen sagt mehr über erstere als solche denn über artifiziell künstlerische Äußerungen als solche!
Nachdem ich nun schon einige Fachartikel über KI mit der obligatorischen einleitenden Dalle-E-Illustration – recht praktisch natürlich, weil so jeder sein eigener Urheber sein kann – gesehen habe, fängt mich diese Art der Illustration wie auch besagter Lyrik, von Musik ganz zu schweigen, als künstliche Kunst an zu langweilen, entsetzlich zu langweilen, weil KI kann Picasso oder Munch zwar reproduzieren, sie
neu erfinden aber
…
das kann sie nicht
Nur, in dem Moment, in dem diese Erkenntnis ganz allgemein die Köpfe der KI-Apologeten durchdringen und sich dort festsetzen wird, wird es unmöglich sein, um noch umzusteuern – unabänderlich, weil unwiderruflich da unwiederbringlich das, was war.